Train Stages: Pretrain, Mid-Train(CT), SFT, RL
导言
模型训练,为什么需要这么多阶段,每个阶段的独特职责和意义是什么。
导言
模型训练,为什么需要这么多阶段,每个阶段的独特职责和意义是什么。
导言
导言
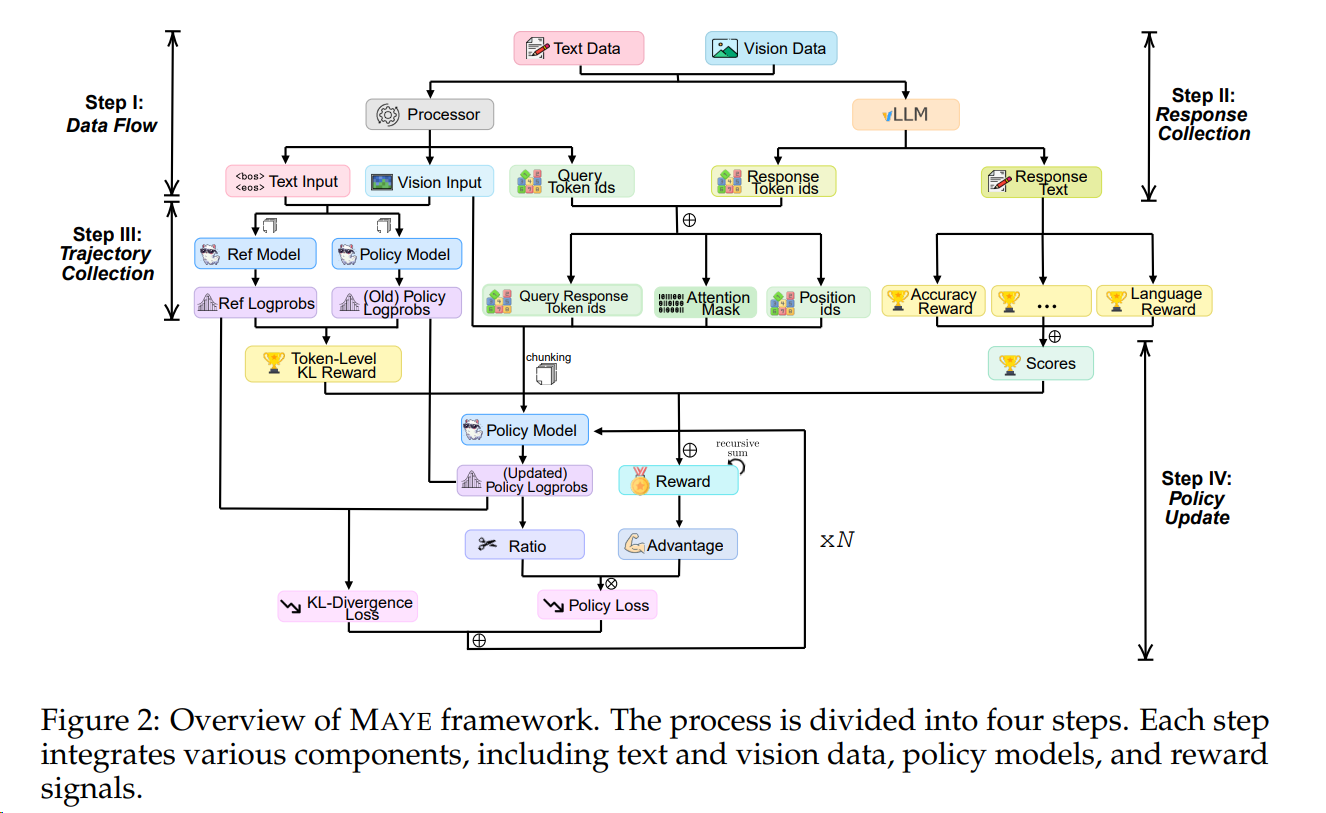
快速调研多模态强化学习及其ai infra(verl类似)的下一步方向、技术点和与LLM RL的差异点:
导言
导言
为什么之前认为金融只是调配资源,并不产生生产价值的我。也会想搞量化。
导言
第一次相亲(第二次见面)
导言
自动驾驶 VLA(Vision-Language-Action)模型中,VLM 和 DiT 是两个核心组件。但很多人会有一个常见误解:DiT 是用来生成图片的。实际上,在自动驾驶场景中,DiT 更多是作为动作/轨迹生成器,而非图像生成器。
VLM 负责"看懂路况和指令",DiT 负责"生成一段连续、平滑、多模态的驾驶动作/轨迹"。
导言
多模态生成模型的推理速度一直受制于diffusion模型的多步去噪,这也限制了RL的迭代速度。为此DMDR解决了这个问题。可以结合DiffusionNFT+DMDR
导言
第一次相亲