Ideas around Vision-Language Models (VLMs) / Reasoning Models
导言
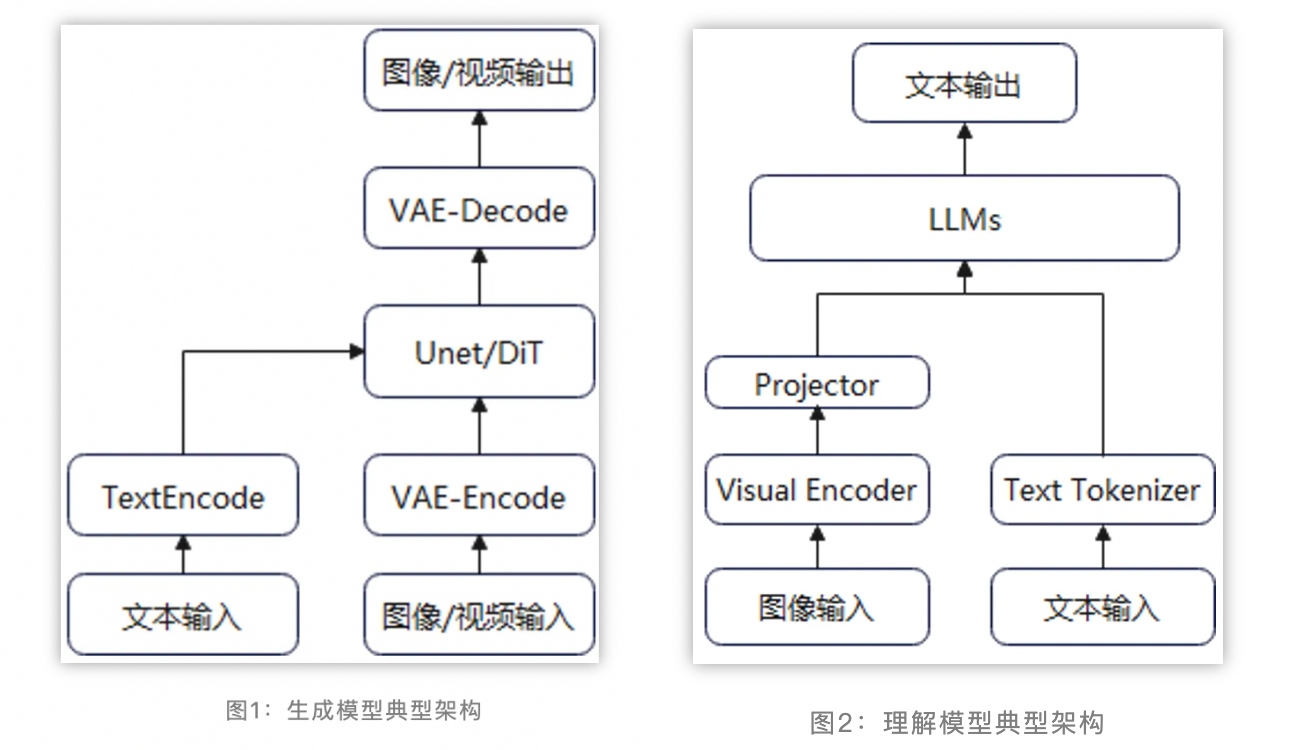
当前主流的多模态理解模型一般采用视觉编码器 + 模态对齐 + LLM的算法流程,充分复用已有视觉编码器的理解能力和LLM的基础能力。训练过程一般分为多个阶段,如先进行模态对齐的一阶段预训练,然后进行二阶段的参数微调。
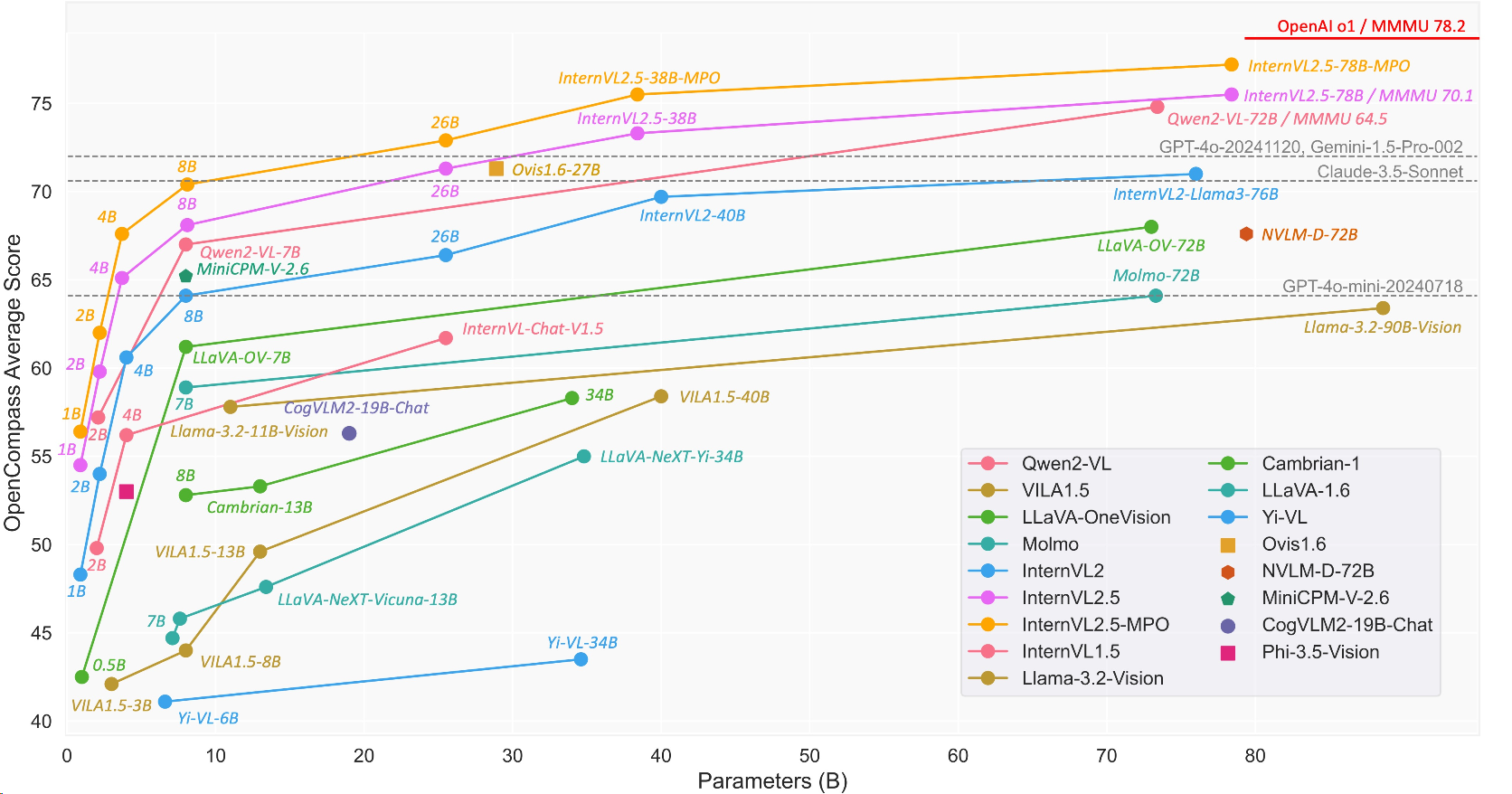
排行榜:
MLLM 概念
MLLM (Multimodal Large Language Model) = Multimodality Understanding + LLM (Large Language Model)1
基础¶
两分类¶
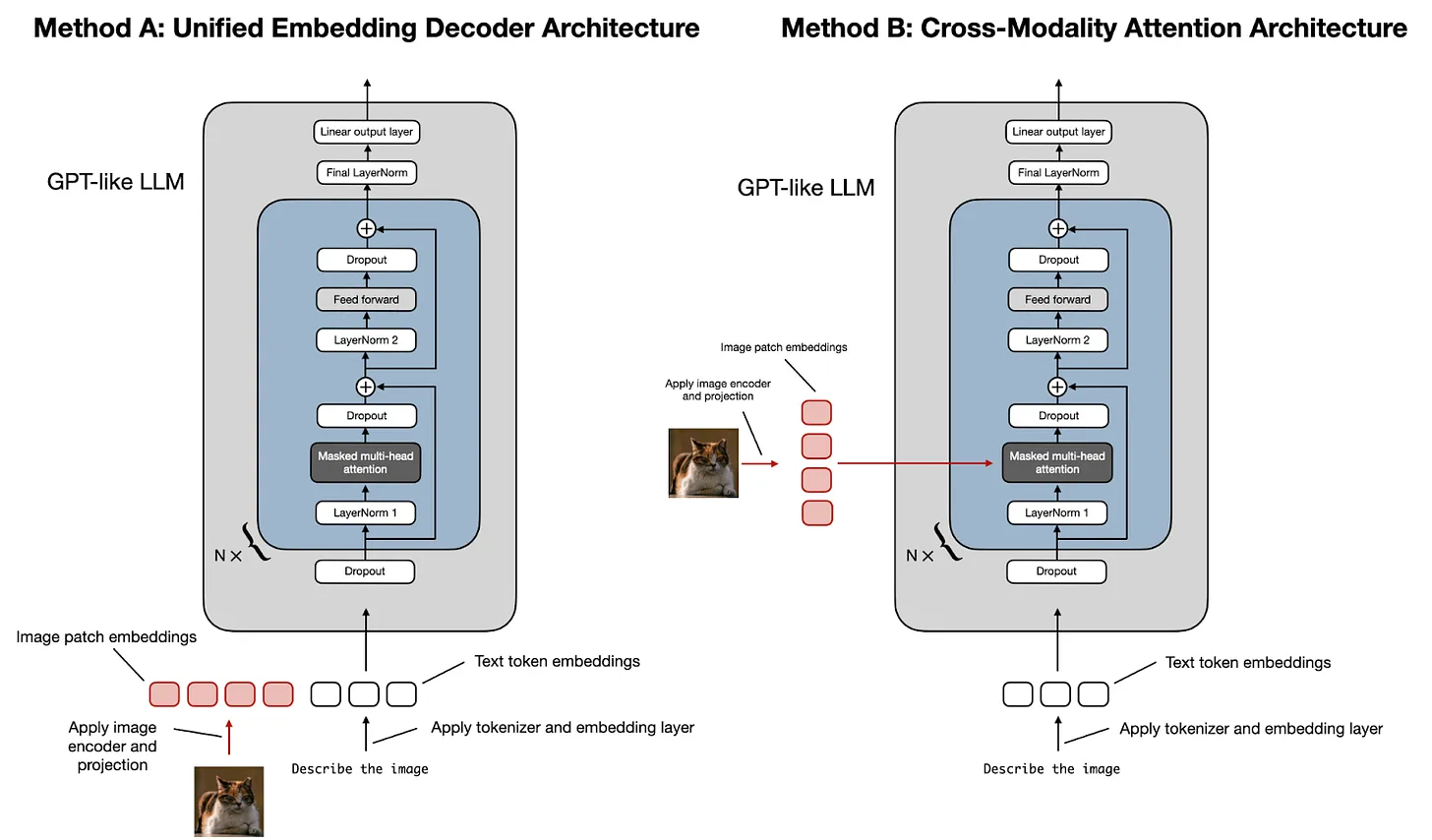
- 统一嵌入-解码器架构2
- 使用单个解码器模型,很像 GPT-2 或 Llama 3.2 等未经修改的 LLM 架构。在这种方法中,图像被转换为与原始文本token具有相同嵌入大小的token,从而允许 LLM 在连接后同时处理文本和图像输入token。
- 跨模态注意力架构
- 采用交叉注意力机制,将图像和文本嵌入直接集成到注意力层中。
三组件:¶
- A pre-trained modality encoder
- The encoders compress raw information, such as images or audio, into a more compact representation.
- 视觉编码器与NLP中的Encoder类似,可以直接选择pre-train好的, 比如CLIP
- A pre-trained LLM
- A modality interface to connect them
- 考虑到以端到端方式训练大型多模态模型的成本很高,为了使用Pre-trained LLM和Pre-trained modality encoder,我们需要去设置一个模块,这个模块可以去将不同模态的经过encoder后的信息融合。
- Learnable Connector:通过learnable connector这个模块,可以将多模态信息融合成可以让LLM理解的信息。融合的模型可以根据融合的最小颗粒度划分:token-level和feature-level。 1. feature-level fusion和token-level fusion的本质区别在于是否更改LLM或是ViT的内部结构:若是仅在两个组件之间增加一个额外的组件(例如Q-former)则是token-level fusion;若是更改了LLM或是ViT的内部结构,例如加入了额外的模态融合层,则是feature-level fusion。
- Expert Model:专家模型,例如image caption模型,可以将图片转化成描述文字,这样多模态的输入可以被转化成单模态的输入。由此只需要进行单一模态建模即可。
图文编码¶
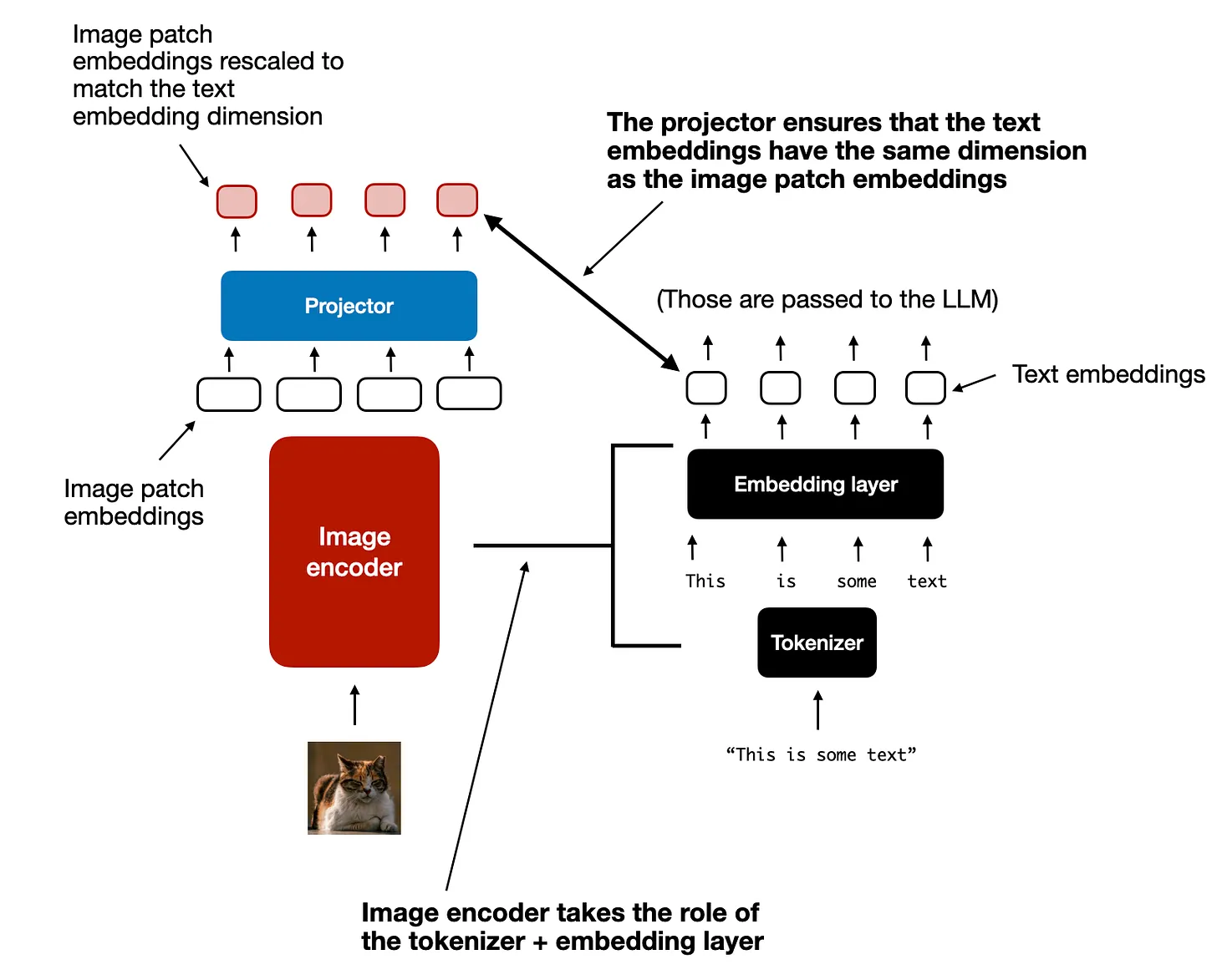
- 图像编码(image encoder)等于文本的分词器(tokenizer)+嵌入层(Embedding layer)
- projector 有时也叫 adapter, adaptor, or connector,用于对齐图文的维度。
自注意力(Self-Attention)与交叉注意力(Cross-Attention)
在交叉注意力中,与自我注意相反,我们有两个不同的输入源,如下图所示:
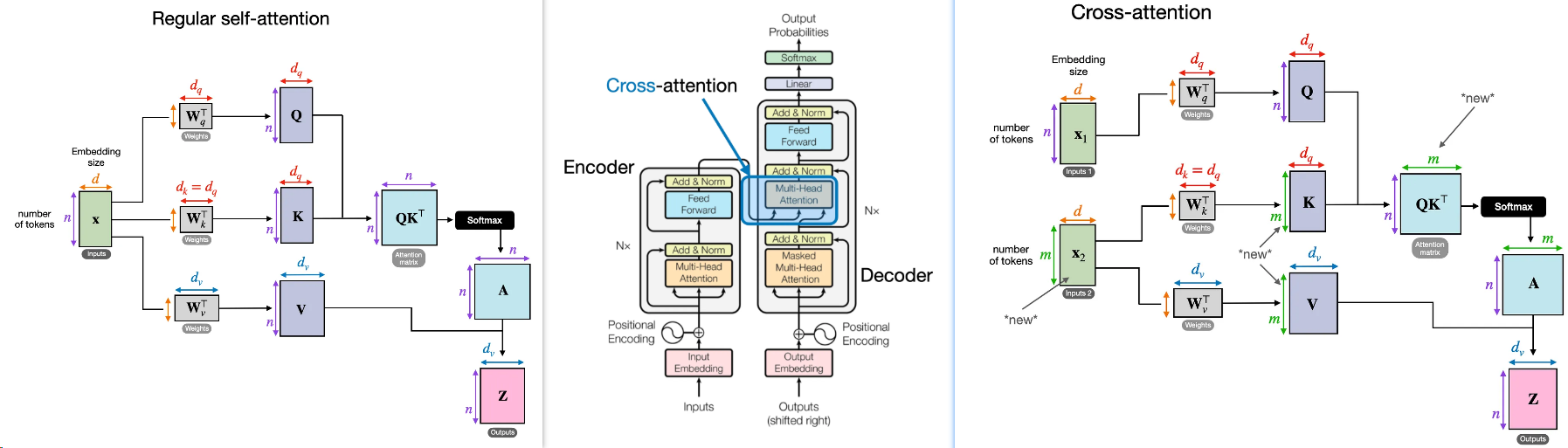
是Transformer模型中的两种核心机制,它们在功能、输入来源和应用场景上有显著区别,以下是详细对比分析:
| 特征 | Self-Attention | Cross-Attention |
|---|---|---|
| 输入来源 | Query、Key、Value均来自同一序列(如编码器输入) | Query来自一个序列(如解码器),Key/Value来自另一序列(如编码器输出) |
| 功能目标 | 捕捉序列内部的长距离依赖关系 | 建立两个不同序列或模态间的关联关系 |
| 典型场景 | 文本编码(句子内部词关联)、图像特征自相关提取 | 机器翻译(编码器-解码器交互)、多模态融合(文本-图像对齐) |
示例:
在机器翻译中,自注意力用于编码器内部分析源语言句子的语法结构,而交叉注意力让解码器在生成目标语言时动态聚焦源语言的关键信息。
在Transformer架构中,两种注意力通常配合使用:
- 编码器:仅用自注意力,提取输入序列的全局特征(如BERT的文本编码)。
- 解码器:
- 自注意力层:处理已生成的目标序列(如翻译结果的前半部分),保证自回归生成的一致性。
- 交叉注意力层:将目标序列(Query)与编码器输出(Key/Value)关联,实现跨语言信息传递。
自注意力与交叉注意力共同构成了Transformer模型处理复杂依赖关系的核心能力。自注意力聚焦序列内部结构,适用于单模态特征提取;交叉注意力实现跨序列信息融合,是多任务与多模态模型的关键组件。两者的结合(如编码器-解码器架构)在机器翻译、文本生成等任务中展现了强大的性能。
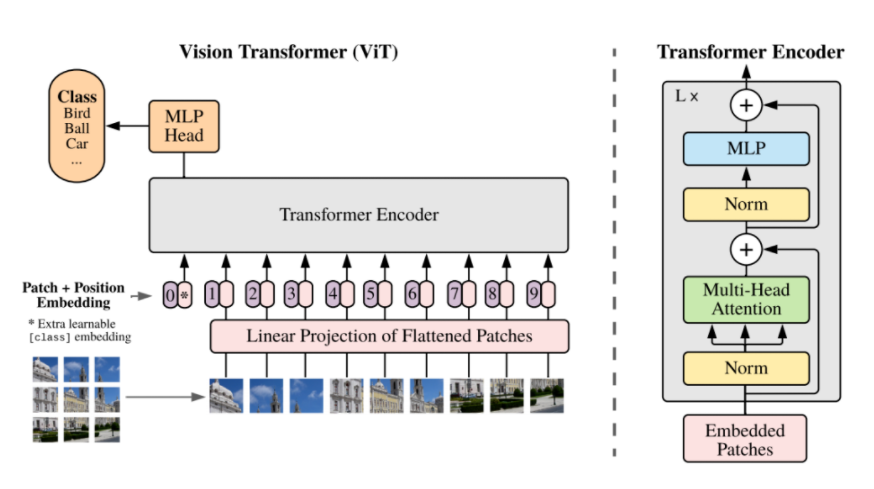
ViT¶
ViT(vision transformer)是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。
ViT的思路很简单:
- 直接把图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding,
- 由于transformer的输入就是a sequence of token embeddings,所以将图像的patch embeddings送入transformer后就能够进行特征提取从而分类了。
ViT模型原理如下图所示,其实ViT模型只是用了transformer的Encoder来提取特征(原始的transformer还有decoder部分,用于实现sequence to sequence,比如机器翻译)。
2601 Step3-VL-10B 阶跃星辰¶
模型在 10B 规模以下的模型中始终表现最优,并能媲美甚至超越规模大 10×–20× 的开源模型(如 GLM-4.6V 106B-A12B、Qwen3-VL-Thinking 235B-A22B)以及顶级闭源旗舰模型(如 Gemini 2.5 Pro、Seed-1.5-VL)。
架构
- 视觉编码器:PE-lang(Language-Optimized Perception Encoder),1.8B 参数。
- 解码器:Qwen3-8B。
- 投影层:两个连续的 stride-2 层(实现 16× 空间下采样)。
- 分辨率:多裁剪策略,由 728×728 全局视图与多个 504×504 局部裁剪组成。
训练流程
- 预训练: 单阶段、全参数解冻策略,使用 AdamW 优化器(总计:1.2T tokens,370K iterations)。
- 阶段 1:900B tokens。
- 阶段 2:300B tokens。
- 监督微调(SFT): 两阶段方案(总计:约 226B tokens)。
- 阶段 1:文本与多模态比例 9:1(约 190B tokens)。
- 阶段 2:文本与多模态比例 1:1(约 36B tokens)。
- 强化学习: 总计 >1,400 次迭代。
- RLVR:600 次迭代(任务:数学、几何、物理、感知、grounding)。
- RLHF:300 次迭代(任务:开放式生成)。
- PaCoRe Training:500 次迭代。
SFT 2 RL的规模突破:重点是把计算转化为智能的效率
将计算资源从预训练转向强化学习(RL)。 强化学习的规模化已被证明能够带来持续且不易饱和的性能跃迁,这是单纯依赖预训练所无法长期维持的。我们计划大幅度地将计算资源重心转向 RL。
通过在深度(顺序推理能力)和宽度(并行探索能力)两个维度上进行全面规模化扩展,我们希望挖掘出高价值的感知与推理轨迹,从而推动各个模型规模的多模态智能上限不断提升。
RL算法选择:PPO¶
基于PPO+GAE,之前的工作:
- Open-Reasoner-Zero(2503, 阶跃星辰&清华):LLM领域,传统观点认为,要提升模型的推理能力需要复杂的训练方法。但这项研究却发现:1)使用最基础的PPO算法;2)采用简单的规则化奖励函数 3)不需要任何KL正则化。就能实现模型性能和响应长度的持续提升。这个发现颠覆了我们的认知,印证了"苦涩教训"(bitter lesson):真正重要的是训练数据、模型规模和训练次数的规模,而不是设计的复杂度。仅用1/30的训练轮次就超越了DeepSeek-R1-Zero。
- Open Vision Reasoner(2507, 阶跃星辰)在Open-Reasoner-Zero,将基础PPO变成了PPO+GAE,把领域从LLM迁移到了MLLM,通过精细的数据集构建,2M的cold start SFT,1000步的RL实现了开源SOTA。
说实话25年基本都是GRPO-family的算法,25年11月才开始系统看RL理论,前面这两篇确实漏了。值得关注的是该工作的RL实验,reward竟然持续上升,这到底是PPO相对GRPO的优势,还是奖励设计的功劳。但是600步后,下游评测集分数还是饱和了,并且只靠RLVR出现两种截然不同的动态:
- 推理任务(如 STEM、谜题): 模型通过增加推理步骤(Chain-of-Thought)来提高正确率,即“越想越细”。
- 感知任务(如 OCR、计数、定位): 模型表现出“长度缩减”(Length Diminishment)。为了追求确定性和效率,RL 会剪除冗余的探索步骤,将概率集中在单一的确定性答案上,导致模型不愿意进行长链的“视觉思考”。
结论: 仅靠 RLVR,模型在感知类任务上无法通过增加推理长度来提升性能,甚至会抑制复杂的视觉推理过程。
解释:“缺失痕迹假说”(The "Missing Trace" Hypothesis)。 人类在看东西时(比如找一根针),会有“视线扫过、试错、聚焦”的心理过程,但这些过程在训练数据中通常是不可见的(数据只给了结果,没有描述“我先看了左边,没找到,再看右边”)。 因为 RLVR 缺乏这些“认知痕迹”的监督信号,模型很难自发地学会这种复杂的视觉搜索策略。
后续通过PaCoRe的工作弥补。PaCoRe 的作用: 它作为一种测试时(Test-time)的计算扩展策略,强制模型显式地生成多个假设(Proposals),然后进行交叉验证。这相当于在不改变模型参数的情况下,通过算力“喂”给模型一个思考框架。
奖励设计¶
没有依赖单一的奖励信号,而是设计了一套分叉的奖励框架(Bifurcated Reward Framework),针对不同类型的题目采用了完全不同的打分逻辑。
核心理念:分叉奖励机制;奖励系统分为两大类:可验证任务(Verifiable)和不可验证任务(Non-Verifiable)。这种区分解决了“一刀切”打分导致模型在某些领域(如创意写作)受限,而在另一些领域(如数学)不准的问题。
A. 可验证任务奖励(Verifiable Rewards)——追求“绝对正确” 针对有标准答案的任务(如数学、物理、OCR、定位),系统追求逻辑的严密性和结果的精确性。
- 感知奖励(Perception Rewards):
- 针对场景: 视觉定位(Grounding)、目标检测。
- 设计细节: 不像传统方法只给对错的二值奖励,这里采用了基于距离的奖励塑形(Distance-decay reward shaping)。
- 原理: 模型输出的坐标框与标准答案的 IoU(交并比)或欧氏距离越近,奖励越高。这种“渐进式”的反馈让模型能微调自己的视觉定位能力,而不是盲目试错。
- 基于模型的验证(Model-Based Verification):
- 针对场景: 通用视觉问答、复杂推理。
- 设计细节: 使用超大模型 GPT-OSS-120B 作为裁判。
- 原理: 这比简单的字符串匹配(String Matching)强得多。它能识别语义等价性(比如“2+2”和“4”是等价的,或者数学推导步骤顺序不同但逻辑正确),并能检测过程一致性(防止模型答案蒙对了但推理过程是错的,即 Penalizing false positives)。
B. 不可验证任务奖励(Non-Verifiable Rewards)——追求“人类偏好” 针对没有标准答案的任务(如开放对话、创意写作),系统转向对齐人类价值观和行为约束。
- 生成式奖励建模(GenRM):
- 设计细节: 采用成对比较(Pairwise preference)框架。
- 原理: 不直接给分,而是让奖励模型判断当前模型的回答是否比“老师模型”(Teacher Model)的回答更好。它不仅看结果,还显式地判断推理过程的质量,以此区分两个看似都合理的回答哪个更优。
- 行为正则化(Behavioral Regularization):这是一套“防作弊”机制,作为惩罚项(Penalty Terms)加入奖励计算。提升下面三项能力:
- 语言一致性: 惩罚乱码、中英混杂(Code-switching)。
- 引用验证: 一旦检测到模型编造参考文献或链接,奖励直接归零(Zero the reward)。
- 认知校准: 惩罚在模糊问题上表现出过度自信的言论,鼓励模型在不确定时表达“我不知道”。
PaCoRe 2601 阶跃星辰&清华¶
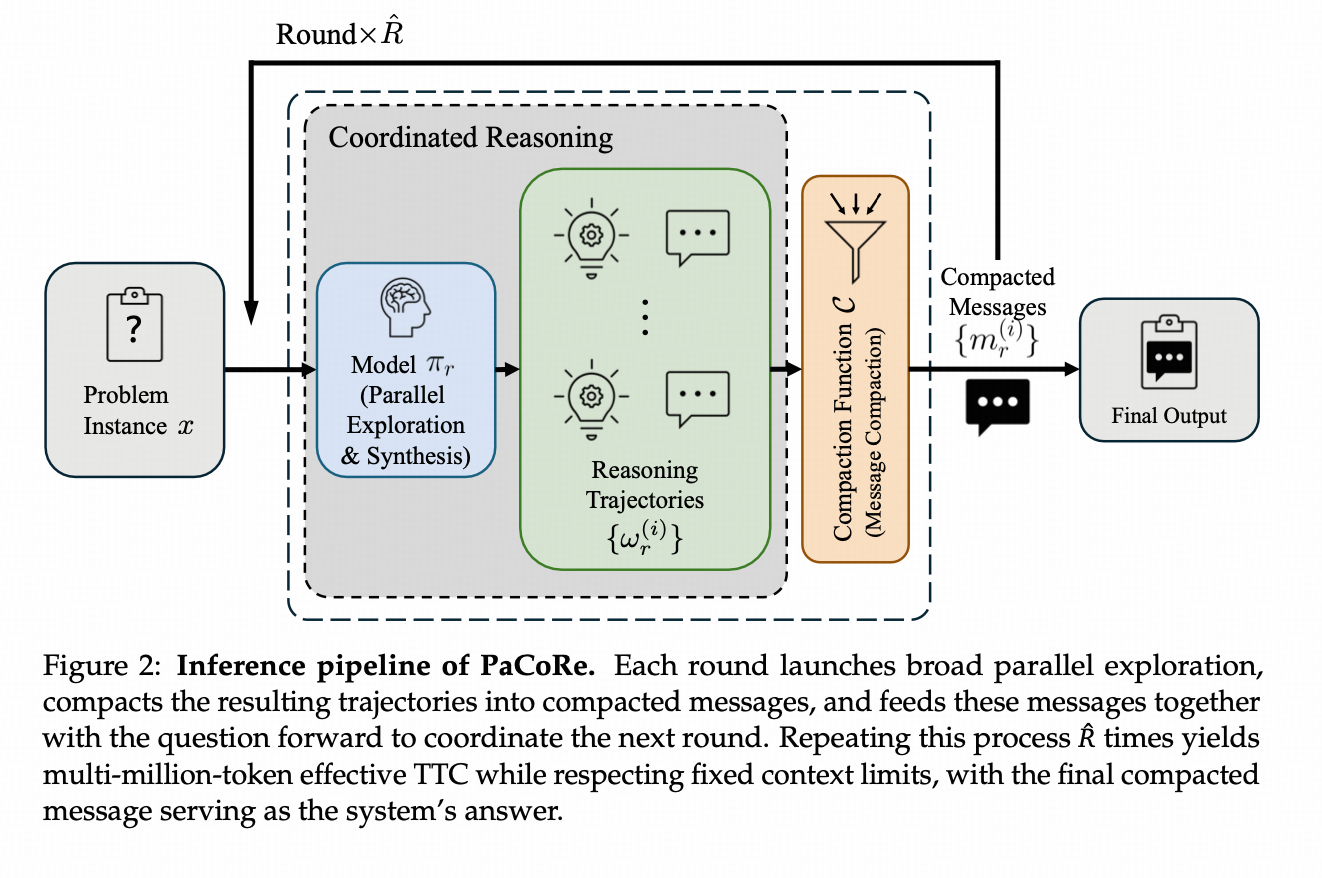
PaCoRe框架由训练和推理管道组成。
- 推理管道通过协调并行探索来大规模扩展测试时计算(TTC),远远超出顺序推理的限制,同时独立于上下文约束。具体来说每一轮推理都会启动广泛的并行探索,将产生的轨迹压缩为紧凑的消息,并将这些消息与问题一起传递给模型,以协调下一轮。重复这个过程R次,在尊重固定上下文限制的同时,产生数百万个令牌的有效TTC,最终的紧凑消息作为系统的答案
- 训练过程采用大规模、基于结果的强化学习(PPO+GAE+ORZ,700步RL),教会模型合成来自不同轨迹的见解并生成高质量的最终答案所需的技能。
PaCoRe 建立了一条通往大规模测试时扩展(Test-Time Scaling)的无限路径。通过围绕“并行协同”构建推理架构并针对“综合能力”进行训练,我们可以将测试时计算扩展到数百万 Token,从而允许较小的开放权重模型(Qwen3-8B-Base)在复杂任务上超越专有的前沿系统(Qwen3-235B-Thinking)。
小结:阶跃星辰在如何加速把token/算力通过RL变成智能的方向上持续发力,PaCoRe和Open-Reasoner-Zero这些LLM领域的工作思路也是无缝迁移到MLLM上了。展示了在RL方向也是能力大砖飞的。
2511 [OCR] HunyuanOCR¶
- 背景:
- 广义OCR领域包括:文字定位(Spotting)、版面解析(Parsing)、信息抽取(IE)、视觉问答(VQA)和文本翻译
- 传统OCR领域模型过于偏科,只能解决上面的某一种;通用的视觉语言模型(VLM)虽然强大,但又大又慢,部署成本高
- 架构特点:
- 语言模型小0.5B;XD-RoPE;
- 第一次使用GRPO

2510 HunYuan Vision¶
- October 6, 2025: hunyuan-vision-1.5-thinking ranked 3rd on LmArena, the best performing model in China.
- 暂无技术报告
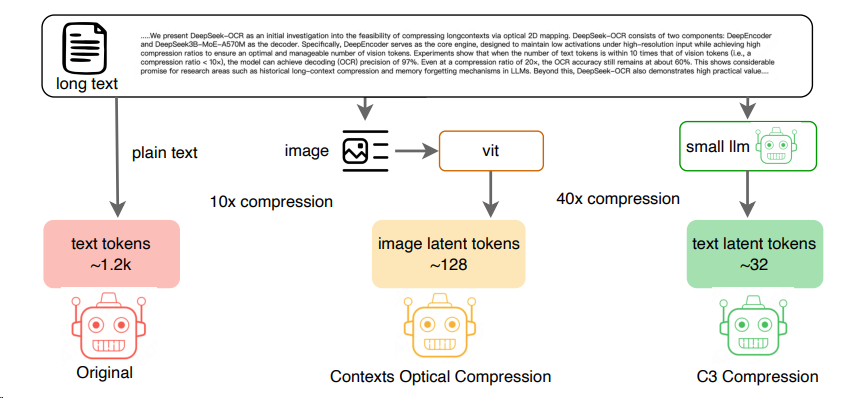
2510 [OCR] Deepseek-OCR¶
- 架构特点:在传统Vit的Clip前引入SAM-Base来实现窗口注意力机制下的更高图片Token的压缩
- 启示:对于LLM领域用光学来压缩文本能实现:1. 输入token的减少;2. 实现遗忘机制。
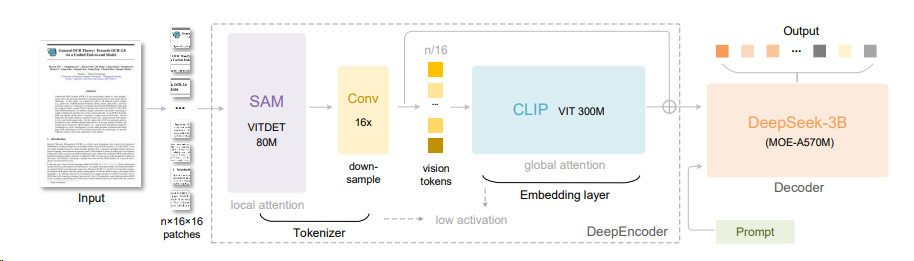
C3-Context-Cascade-Compression3(美团) : 反驳了Deepseek-OCR的观点,跳过视觉模态的中间态,纯文本压缩(token 压缩)也可以让LLM“一目十行”。(之前相似文章4)
2509 qwen3vl¶
特点:
- MRoPE-Interleave
- DeepStack: 不同于之前Vit结束后,embedding内容到LLM,现在将以往多模态大模型(LMM)单层输入视觉tokens的范式,改为在大型语言模型 (LLM) 的多层中进行注入。
2508 GLM4.5V 清华智谱¶
- 特点: 开源迁移时,glm4.1v和qwen2.5vl有相似之处,glm4.5v和qwen3也有相似处。
- Thinking(推理模式):视觉编码器(基于 AIMv2-Huge)、MLP 适配器 和 大型语言模型(LLM)解码器(GLM-4-9B-0414 或 GLM-4.5-Air)。
2508 Internvl 3.5¶
- 架构:InternVL-ViT + Qwen3
- 被评论区质疑和Qwen2.5VL差不多, 竞技场没有模型。
2411 DeepSeek-VL2¶
- SigCLIP改进了CLIP的loss
2408 Qwen2 VL 72B¶
- 亮点:能处理各种分辨率和长宽比
- 技术要点:
- 引入了naive dynamic resolution技术,支持灵活处理不同分辨率的输入图像和视频
- 创新性地提出了多模态旋转位置编码(M-RoPE),这有助于实现更高效的跨模态信息融合,从而增强了模型对于文本和视觉数据的理解能力
- 构建了一个统一的图像和视频理解框架,其中图像被视作两个相同的帧来处理,以维持与视频处理逻辑的一致性
- 并采用3D tubes替代传统的2D patches方法,进一步提升了对长时间序列视觉内容的理解深度

2407 InterlVL2 76B¶
上海人工智能实验室(上海AI实验室)联合清华大学、香港中文大学、商汤科技等机构开源新一代书生·视觉大模型(InternVL)。性能和Qwen属于同一水平。