VeRL Performance Optimization
导言
MFU / SMA 低不一定说明 kernel 慢,也可能是 rollout、reward、checkpoint、通信、异步队列或 token 分布造成的等待。性能优化的第一步不是开特性,而是建立 E2E 性能模型。
1. 性能模型¶
需要把每个阶段进一步拆成:
- compute time
- memory time
- communication time
- scheduling time
- queue wait time
- data preprocess time
2. 瓶颈分类¶
- compute-bound:算力成为主要限制。
- memory-bound:访存、激活、KV cache 或通信 buffer 成为主要限制。
- communication-bound:all-gather、reduce-scatter、ring attention 等通信占主导。
- scheduling-bound:动态 batch、队列、Ray 调度或 worker 切换开销明显。
- data-bound:数据加载、reward 函数、后处理成为瓶颈。
3. 特性到瓶颈的映射¶
| 特性 | 可能改善的瓶颈 | 对 MFU / SMA 的作用 | 主要风险 |
|---|---|---|---|
| dynamic batch | padding waste / token packing | 提高有效 token 计算密度 | 峰值显存不稳定 |
| SP / CP | activation / long context | 支持更大 seq 或 batch | 通信复杂度增加 |
| TQ | 待验证 | 可能改善调度或队列等待 | 含义和适用场景待确认 |
| FullAsync | stage idle / bubble | 提高 E2E 设备忙碌度 | staleness 和复现风险 |
| one-step offset | 同步边界等待 | 进一步减少等待 | policy lag 风险 |
| mooncake checkpoint | checkpoint blocked time | 提高长跑有效训练时间 | 环境依赖与恢复语义 |
| inference serving | 推理资源隔离 | 提高推理资源弹性 | 网络和权重同步风险 |
4. BSHD micro-batch padding¶
PR 状态
verl-project/verl#6901 已在 2026-07-02 合入,merge commit 是 561a4b03a11b34446e44267c2e84c4bbf63585f5。标题为 [megatron, perf] feat: pad BSHD micro-batches to mini-batch max seq_len。它新增 actor_rollout_ref.actor.megatron.pad_bshd_to_minibatch_max,最终合入版本把默认值改成 True,但只在 use_remove_padding=False 的 Megatron BSHD path 生效;默认 THD / sequence packing path 仍是 no-op。
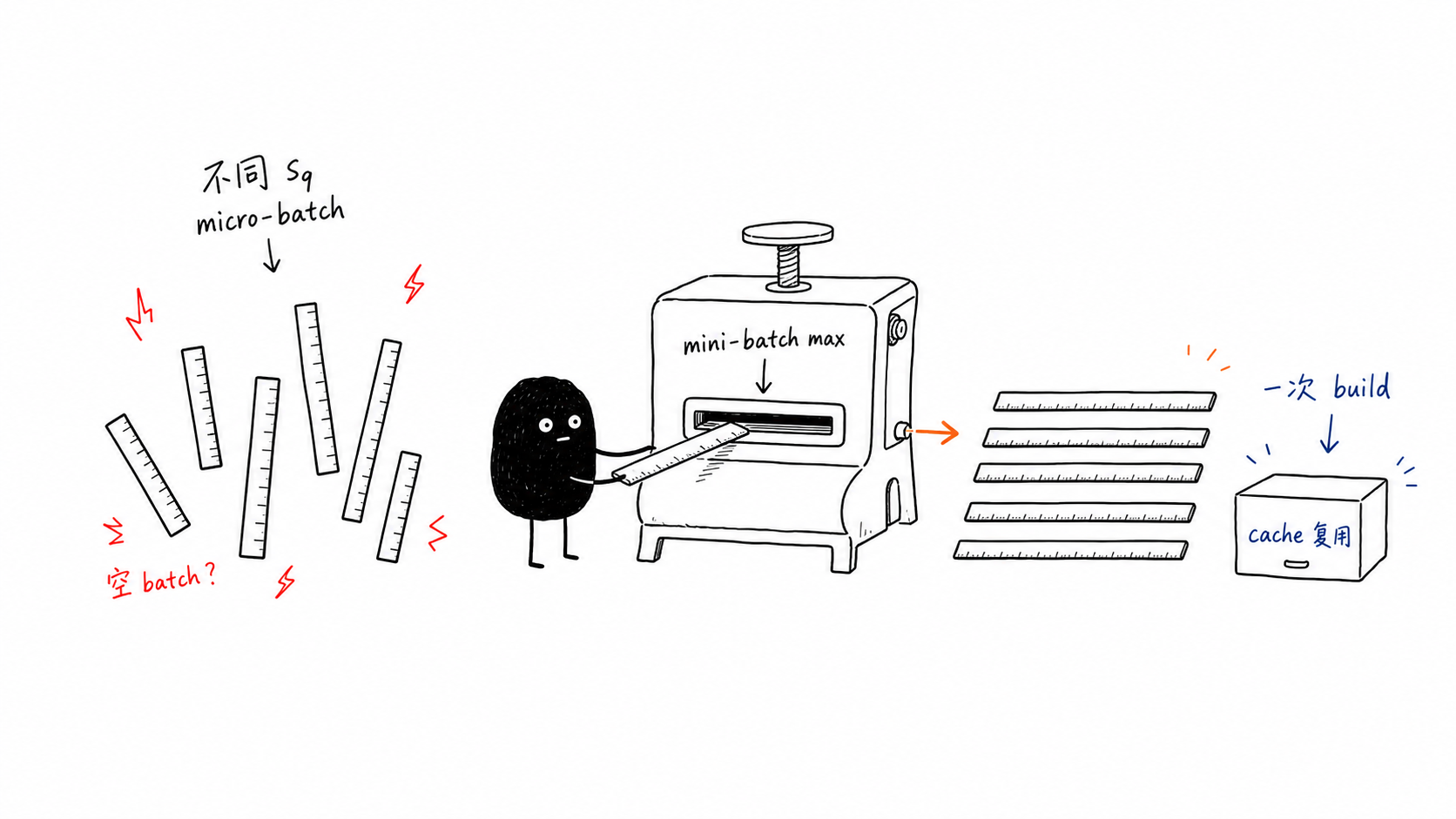
这个 PR 的关键点不是“少 padding”,而是 用更统一的 shape 换 cuDNN / TransformerEngine fused-attention plan cache 复用。旧路径里,每个 micro-batch 按自己的 seqlens_in_batch.max() padding;作者报告一个 mini-batch 的 32 个 micro-batch 可能产生 20+ 种 padded s_q。每遇到一个新 shape,cuDNN fused attention 可能在 CPU 侧做一次 Graph Build / plan build,这部分同步开销可能不容易在 Python profiler 里看到。
新增逻辑的路径是:
verl/workers/config/engine.py增加McoreEngineConfig.pad_bshd_to_minibatch_max: bool = True;verl/trainer/config/engine/megatron.yaml和_generated_ppo_megatron_trainer.yaml也同步把默认值改为True。verl/workers/engine/megatron/transformer_impl.py在forward_backward_batch里从 mini-batch nestedinput_ids.offsets().diff().max()计算 raw global max seq_len。- 该值通过 NonTensorData 写入每个 micro-batch 的
forced_max_seqlen,避免 actor / critic / logprob 多路径共享一个易污染的实例属性。 verl/models/mcore/model_forward.py把forced_max_seqlen传给 BSHD 的preprocess_bshd_engine、MTP label / loss_mask、logits processor args,以及 VLM 的build_vlm_attn_mask_bshd。verl/models/mcore/util.py在preprocess_bshd_engine和build_vlm_attn_mask_bshd里使用 forced raw max 覆盖 micro-batch 局部 max;TP / CP / FP8 alignment 仍保留在 util 内部。
关键代码路径可以简化为:
if pad_bshd_to_minibatch_max and not self.engine_config.use_remove_padding and "input_ids" in data.keys():
input_ids_for_max = data["input_ids"]
if input_ids_for_max.is_nested:
global_max_seqlen = int(input_ids_for_max.offsets().diff().max().item())
for micro_batch in micro_batches:
if global_max_seqlen is not None:
tu.assign_non_tensor(micro_batch, forced_max_seqlen=global_max_seqlen)
读这段代码时要注意两点:第一,forced_max_seqlen 来自 mini-batch,而不是 micro-batch;第二,传下去的是 raw max,后续 TP / CP / FP8 alignment 仍在 preprocess_bshd_engine 内部完成。
性能证据¶
PR 作者给出的 benchmark 是 Qwen3.5-35B-A3B,BSHD path,15 step 均值;Verl Fix 表示开启 pad_bshd_to_minibatch_max。
| Stage | Verl | Verl Fix | 变化 |
|---|---|---|---|
| Total Step Time | 534.13s | 397.71s | 1.34x |
| Gen / Rollout | 171.06s | 170.86s | 基本不变 |
| Old Log Prob | 78.38s | 35.45s | 2.21x |
| Actor Update | 247.58s | 154.50s | 1.60x |
| Weight Sync | 11.04s | 10.73s | 小幅变化 |
| Ref Model | 24.73s | 24.84s | 基本不变 |
Old Log Prob + Actor Update 从 325.96s 降到 189.95s,几乎解释了总 step time 的主要改善。这个分布也支持 PR 的根因判断:收益集中在训练侧 attention forward / backward,而不是 rollout 或权重同步。
正确性边界¶
空 batch 风险
PR 的代码 review 已经指出三处 .max() 风险:mini-batch global max 计算、preprocess_bshd_engine、build_vlm_attn_mask_bshd。动态 batching 或 sequence parallel split 下,如果某些 rank 拿到 batch_size == 0,offsets().diff().max() 可能直接触发 PyTorch RuntimeError。
虽然 PR 已合入,继续接入实验矩阵前至少需要补以下验证:
- forced override 单测:
preprocess_bshd_engine(..., forced_max_seqlen=...)对 1D input、top-k trailing dense dim、need_roll=Truelabel、loss_mask 都保持 shape 和语义一致。 - 空 batch / 空 rank:覆盖
batch_size == 0、nested tensor 空 offsets、forced max 为None和非None两类路径。 - VLM path:
input_ids_bshd、attention mask、label、loss_mask 的shape[:2]必须一致,否则 logits processor 会在形状断言处失败。 - TP / CP / FP8 alignment:调用方只传 raw max,alignment 仍由 util 内部处理;需要验证 CP zigzag、TP padding、FP8 padding 后的 padded shape 仍可复用。
- THD 对比:如果目标模型当前已经支持 THD / remove padding,优先比较 THD baseline;这个开关只适合无法稳定走 THD 的 BSHD 过渡场景。
- 默认值回归:合入版本已经默认
True,需要在 BSHD 短样本、长短混合样本和 VLM 样本上确认额外 padding 不会带来显存峰值或吞吐回退。
NPU 适配判断¶
这个 PR 对 Ascend / NPU 的表面代码迁移看起来不重:forced_max_seqlen 传递、nested tensor length 计算、to_padded_tensor、label / loss_mask 同步 padding 都是 PyTorch / Megatron 侧逻辑,不需要写 Ascend 自定义算子。但整体适配应按 L 级评估项处理,因为它的收益来源强依赖 CUDA / cuDNN / TransformerEngine 对新 shape 的 Graph Build / plan cache 成本,Ascend 路径的 torch_npu.npu_fusion_attention、MindSpeed 或其他 NPU attention backend 没有被证明存在同类瓶颈。
| 维度 | 判断 |
|---|---|
| 代码适配量 | S:主要是 shape / padding / config 逻辑,设备相关代码少;若只是复用上游逻辑,不需要写 Ascend 自定义算子 |
| 性能与机制风险 | L:NPU 未证明有 cuDNN / TransformerEngine 同类 plan build 成本,收益机制不能直接迁移 |
| 正确性风险 | 空 batch / 空 rank .max()、VLM BSHD shape 对齐、MTP label / loss_mask、CP / TP / FP8 alignment 都需要补测 |
| 显存风险 | [B,1,S,S] attention mask 随 Smax 二次增长;mini-batch 中一个极长样本可能让所有 micro-batch 付出额外 HBM 和 mask 构造成本 |
| 自动化动作 | 不自动开 NPU 代码 PR;只作为 BSHD fallback 的受控实验项,优先验证 THD / remove-padding 或 NPU 原生变长路径 |
建议在远程 NPU 上只做显式开关对照:固定 seed、同一批长度分布,采集 Total Step、Old Log Prob、Actor Update、tokens/s/per-NPU、HBM peak、AI Core 利用率、host CPU、attention mask 构造时间和长尾极长样本 OOM 风险。只有在 old_log_prob / actor_update 稳定改善,且没有 HBM / OOM / 正确性问题时,再考虑把这个 flag 纳入默认实验配置;默认策略仍应优先尝试 THD / remove-padding。
相关背景可以继续跟踪 NVIDIA/TransformerEngine#2033:该 issue 中也出现了 fused attention 在新 shape 下 CPU 侧 build / compile 停顿的讨论。
5. MFU / SMA 对外解释模板¶
解释模板
对领导或客户解释利用率时,不要只报一个数字。建议拆成:实际计算时间、通信等待、数据等待、队列等待、checkpoint 阻塞、异常重试。
可以按以下结构说明:
- 当前 E2E step time 是多少。
- actor update 计算占比是多少。
- rollout / reward / ref / checkpoint 等非训练阶段占比是多少。
- rank 间 token 和 active time 是否均衡。
- 开启某特性后,减少的是哪一类等待。
6. 实验设计¶
6.1 Baseline¶
- 关闭待验证特性。
- 固定模型、数据、长度分布、卡数和并行策略。
- 记录完整 DFX 指标。
6.2 单特性消融¶
- 只开 dynamic batch。
- 只开 TQ。
- 只开 FullAsync。
- 只开 one-step offset。
- 只开 mooncake checkpoint。
6.3 组合特性¶
- FullAsync + TQ。
- dynamic batch + SP / CP。
- inference serving + FullAsync。
- checkpoint 优化 + 长跑稳定性验证。
7. 交付图表¶
- E2E timeline。
- per-stage time breakdown。
- per-rank utilization heatmap。
- memory timeline。
- feature ablation table。
- MFU / SMA 与 stage idle time 的相关性图。
8. 待验证项¶
- Ascend 平台 MFU / SMA 的准确采集方式。
- GSPO 优化实践文档中的默认配置、适用硬件和实验口径。
- 内部 vLLM 特性的开关、依赖和真实收益。
- 不同长度分布下各特性收益是否稳定。