VeRL TransferQueue
导言
TransferQueue 不是普通 FIFO queue,也不只是 rollout 侧的 token queue。它更像 RL 后训练的数据系统:controller 仍然负责编排训练流程,但大 tensor 的读写、字段就绪状态、样本消费记录和跨 worker 数据传输被拆到独立 data plane 中。
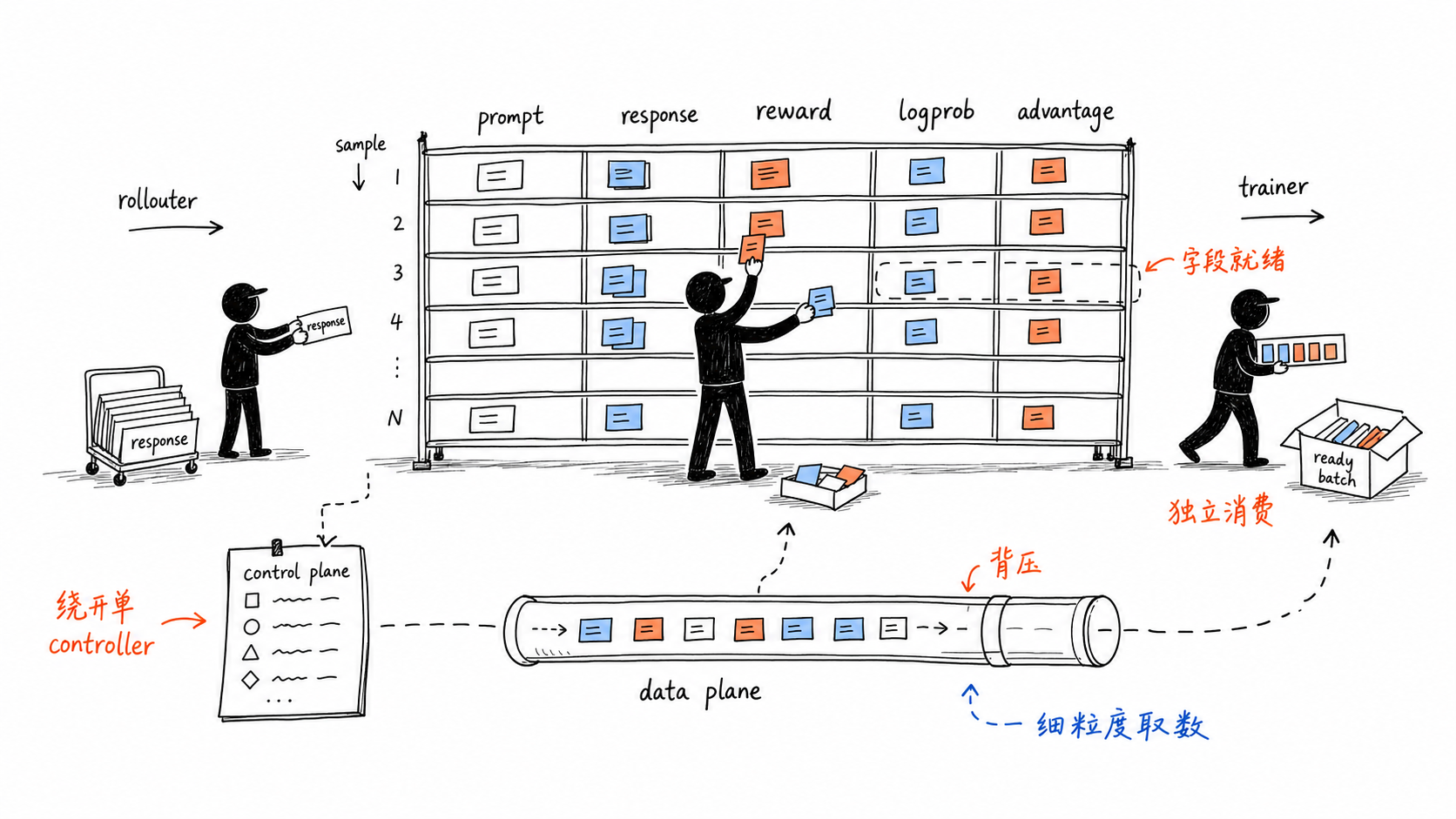
核心问题¶
原始 RayPPOTrainer 路径中,rollout、reward、old logprob、ref logprob、critic 和 actor update 之间的大量 DataProto 会经过单 controller 汇总。小模型或短文本任务里这不一定明显,但一旦进入多模态、长上下文、router replay 或大 batch 场景,controller 的 host memory、对象传输和序列化成本会变成系统瓶颈。
TransferQueue 的核心目标是把两件事分开:
- control flow:谁该执行下一步、哪个 worker 负责哪个阶段、什么时候采样。
- data flow:真实 tensor 从哪里写入、由谁读取、哪些字段已经 ready。
这样 controller 可以继续保持 single-controller 编排和 debug 体验,但不再让所有大 tensor 都经过同一个 Python / Ray 汇聚点。
抽象模型¶
TransferQueue 可以被理解成一个二维数据表:
- 行是 sample:每条 prompt / trajectory 有唯一 key。
- 列是 field:例如
prompt、response、reward、old_log_prob、ref_log_prob、advantage。 - tag 是状态:例如 ready、consumed、stale、partition、policy version。
- metadata 是凭证:worker 通过
KVBatchMeta或类似结构知道要取哪些 key 和 field。
这和一次性搬运整块 DataProto 的区别在于:样本不是“生成完后整体移动”,而是按字段逐步 ready,按消费任务独立读取。
不是更快的 list
TransferQueue 的关键不在队列顺序,而在字段生命周期、消费记录和数据面解耦。把它理解成 FIFO 会低估它对 RL 数据流的作用。
三层架构¶
Control Plane¶
TransferQueueController 追踪每条训练样本的生产状态和消费状态。同一个字段可以被 generate_sequences、compute_log_prob 等不同任务独立消费,不互相干扰。Sampler 则负责自定义取样逻辑,例如按 group、partition、staleness 或 ready 状态取数。1
Data Plane¶
Data plane 通过 StorageManager 抽象对接不同后端。官方文档列出的后端包括 SimpleStorage、Yuanrong、MooncakeStore 和 RayRDT。核心接口可以概括为:
这使得同一套控制语义可以落到不同存储和传输实现上,例如普通 CPU memory、层次化 KV storage、RDMA 传输或 Ray direct transport。
User Interface¶
TransferQueue 提供三类接口:1
| 接口 | 风格 | 适合场景 |
|---|---|---|
| KV API | Redis-like put/get/list/clear |
快速接入、按字段读写 |
| StreamingDataLoader | PyTorch DataLoader 风格 | rank 自动消费 ready samples |
| TransferQueueClient | metadata-based 低层接口 | 自定义 sampler 与完全流式调度 |
verl 集成¶
官方文档把 TransferQueue 集成动机写得很直接:缓解 single controller RayPPOTrainer 的数据传输瓶颈。它在 2026-04-10 通过 PR #5401 集成到 verl,并报告 128 × H100 多模态后训练中取得约 49.1% E2E gain。1
本地上游代码中可以看到 v1 trainer 已经围绕 TransferQueue 组织 replay buffer 和 agent loop:
verl/trainer/ppo/v1/replay_buffer.pyverl/trainer/ppo/v1/trainer_base.pyverl/experimental/agent_loop/agent_loop_tq.pyverl/utils/transferqueue_utils.py
在这个路径里,prompt 可以先以 tag / metadata 形式注册到 TransferQueue;agent loop 生成 trajectory 后写入 response、mask、logprob、reward 等字段;ReplayBuffer 再按 ready 状态和 staleness 采样;后续 old logprob、ref logprob、advantage 和 actor update 围绕同一批 key 读写字段。
性能证据¶
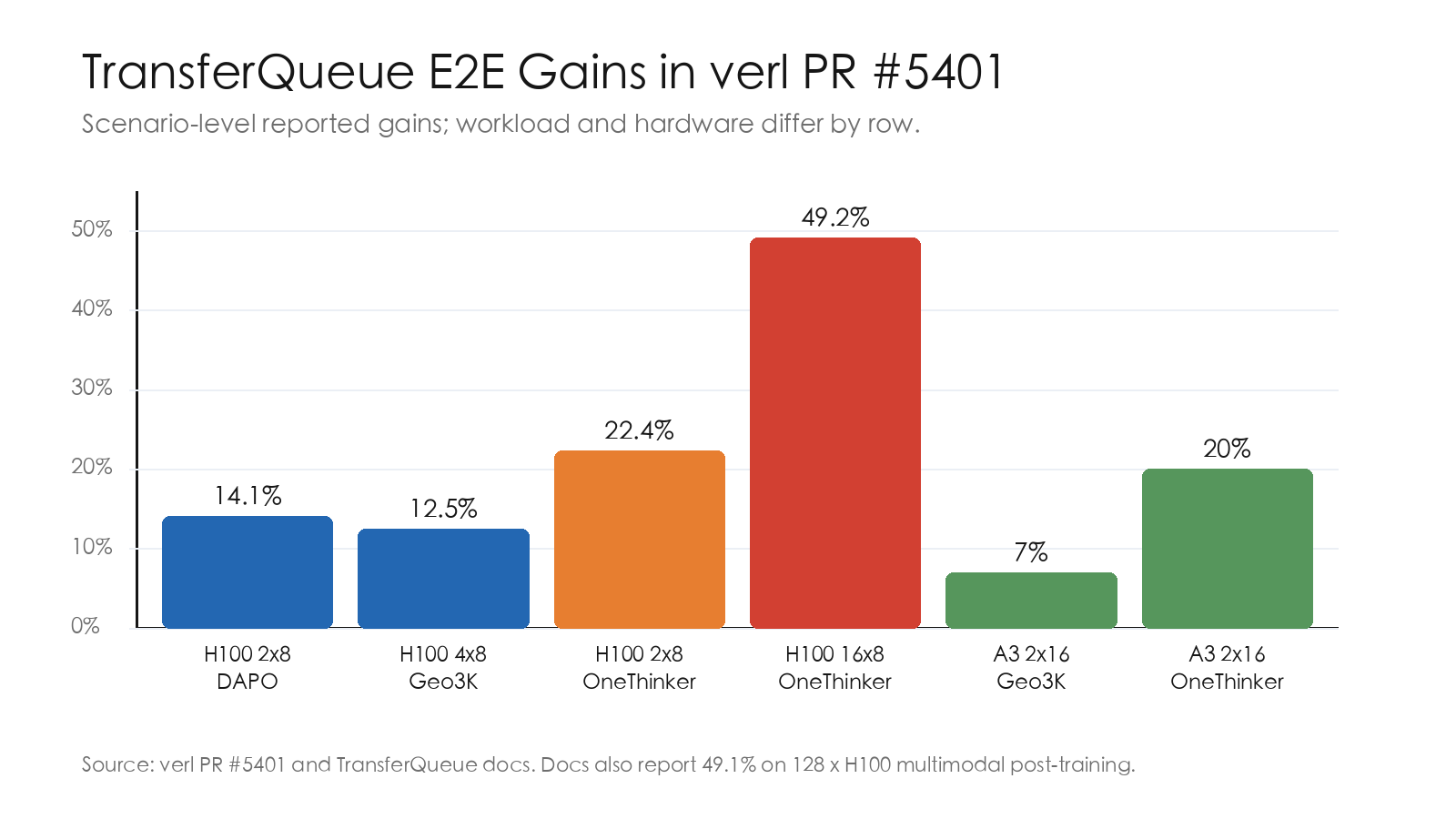
PR #5401 报告了多组 GPU / NPU 场景收益,包括 H100 2×8 DAPO、H100 4×8 Geo3K、H100 16×8 OneThinker 和 A3 场景。官方文档另写 128×H100 多模态后训练取得 49.1% E2E gain。2
这些收益主要来自:
- 少搬大对象:controller 不再成为所有
DataProto的必经点。 - 字段粒度读写:下游只取自己需要的字段。
- 消费状态显式化:同一字段可被多个任务独立消费。
- 生产消费流式化:ready samples 可以更早进入下游,而不是等整批对象汇总。
正确性语义¶
TransferQueue 解耦数据面后,正确性依赖更显式的 metadata。至少要记录:
- sample id / group id
- prompt partition
- policy version
- response mask
- reward source
- old logprob source
- stale / dropped / consumed 状态
- field ready 时间
数据系统也会改变训练
如果 queue 满时丢样本、sampler 改变 group 分布、staleness 过滤不透明,TransferQueue 不只是性能优化,还会改变训练数据分布。任何 TQ 实验都应同时记录吞吐和数据语义指标。
与其它特性的关系¶
- FullAsync 解决 rollout 与 trainer 的 stage bubble。
- TransferQueue 解决样本字段生命周期和 controller 数据瓶颈。
- Router Replay 解决 MoE expert 路径一致性。
- Checkpoint 需要明确 TQ 中 pending / active / consumed 样本的恢复语义。
这几个特性会互相影响,但不应混为一个“异步加速开关”。TransferQueue 更底层:它提供的是数据可见性和数据传输基础设施。
总结¶
TransferQueue 的价值是把 RL 后训练从“controller 搬运大对象”推进到“controller 管 metadata,data plane 管 tensor”。当任务进入长上下文、多模态、大 batch、异步 rollout 或 MoE router replay 场景时,这种解耦会直接影响端到端吞吐、host memory 和 debug 可见性。