AI Model Memory
导言
大语言模型、多模态模型是如何设计来实现高效Mem机制。
导言
大语言模型、多模态模型是如何设计来实现高效Mem机制。
导言
视觉领域的GPT moment要来了吗?4
当前多模态设计中AR和DiT的组合关系,单独学习一下
导言
VeRL 作为RL领域趋势最火的开源仓,值得学习。
导言
VeRL 基于ray的多进程管理,并结合 推理、训练等多个阶段。其E2E时间组成和如何加速都是待研究的课题。
导言
模型训练,为什么需要这么多阶段,每个阶段的独特职责和意义是什么。
导言
导言
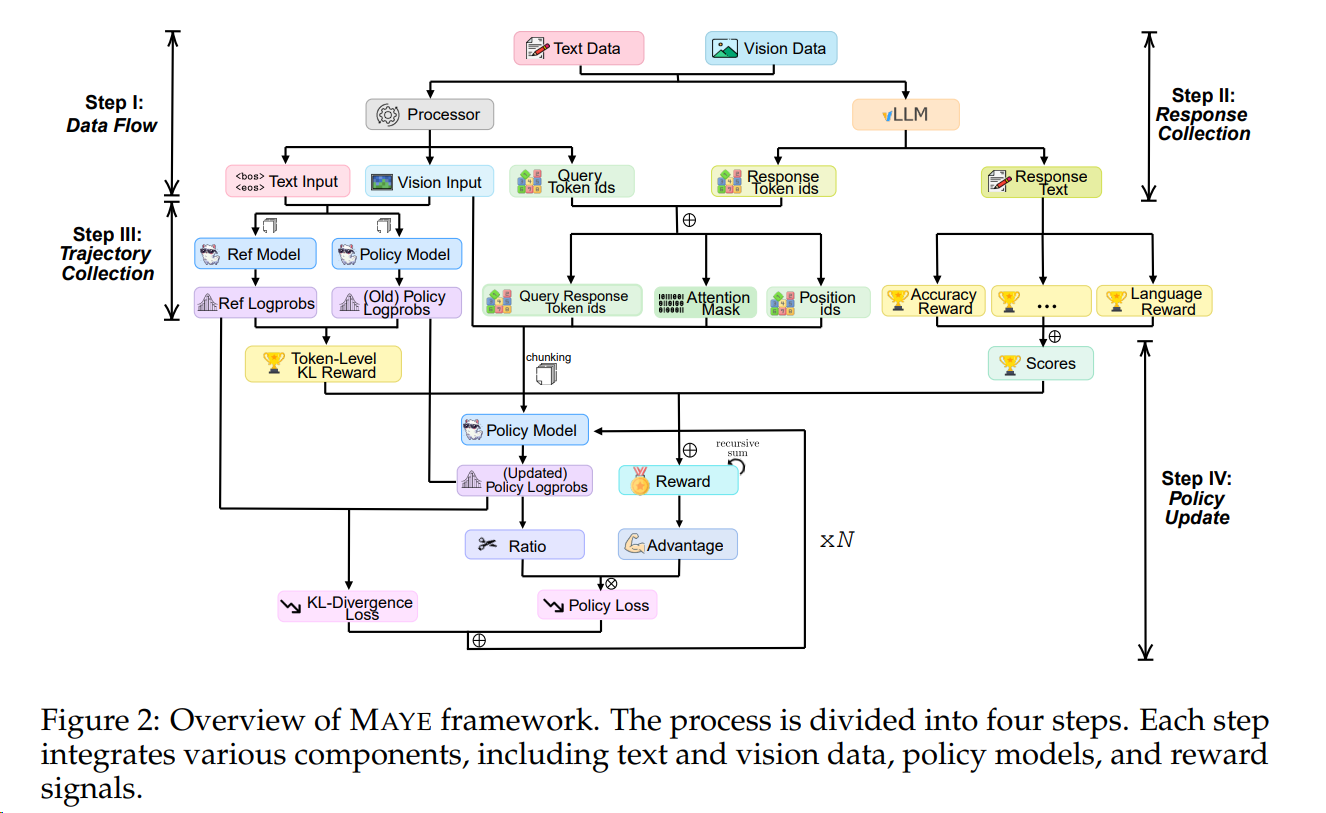
快速调研多模态强化学习及其ai infra(verl类似)的下一步方向、技术点和与LLM RL的差异点:
导言
当前主流的多模态理解模型一般采用视觉编码器 + 模态对齐 + LLM的算法流程,充分复用已有视觉编码器的理解能力和LLM的基础能力。训练过程一般分为多个阶段,如先进行模态对齐的一阶段预训练,然后进行二阶段的参数微调。
排行榜:
导言
vllm 的ray后端属实奇诡,ray stop有残留,flush打印被吞(虽然输出能标记ip,折叠重复,在master输出),ray集群的环境变量固定不变导致DP无法实现多机。
为此考虑使用torchrun实现多机并行。
写得太好了,由浅入深。