导言
- 数据集与数据加载器:学习如何使用torch.utils.data.Dataset和DataLoader来加载和处理数据。
- 数据预处理:介绍常用的数据预处理方法,如归一化、数据增强等。
数据读取整体流程¶
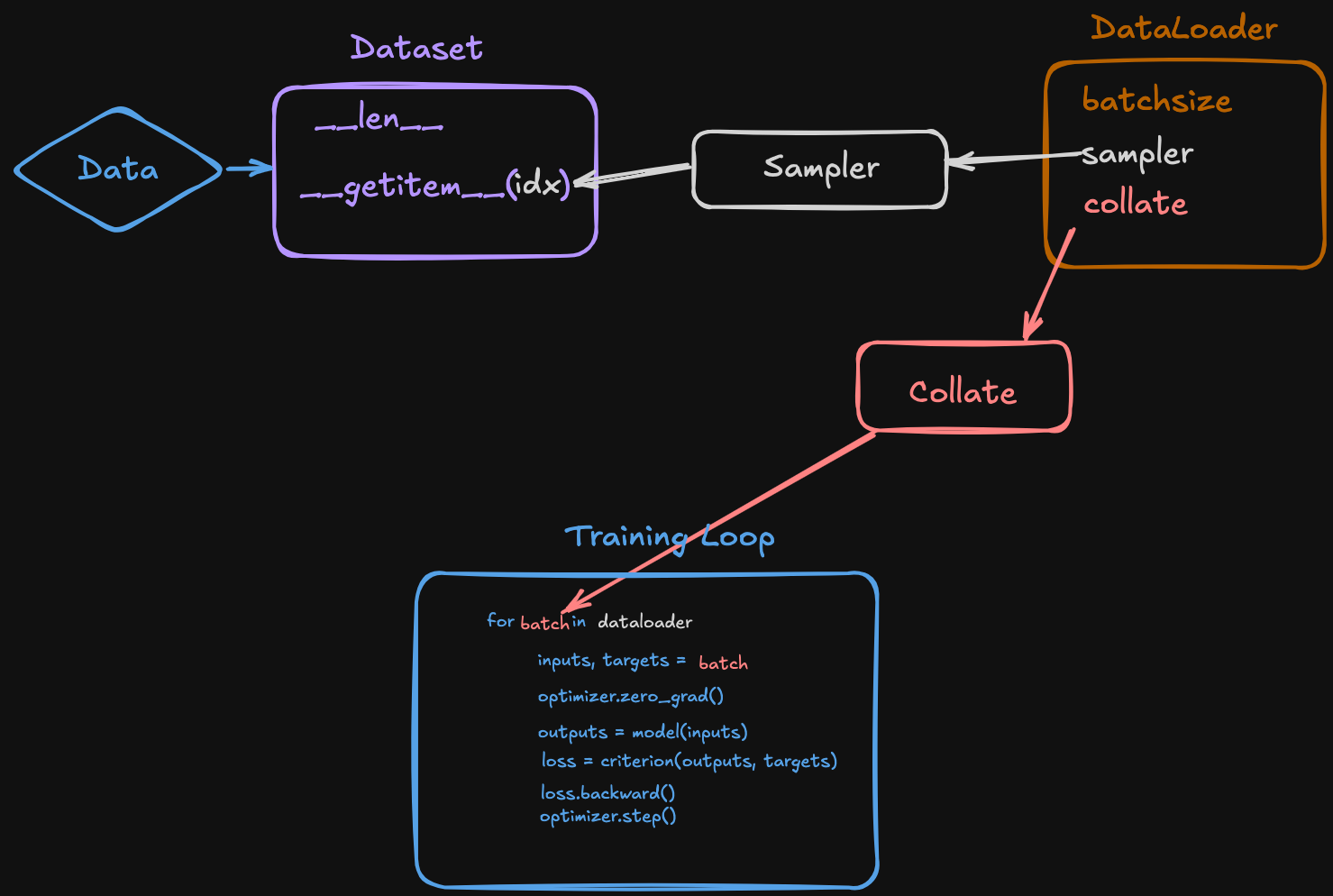
🔑 DataLoader 数据读取的执行流程¶
当你写:
底层其实发生了这些步骤:
1. 初始化 DataLoader¶
- 传入
dataset(必须实现__len__和__getitem__) - 传入采样方式:
sampler或batch_sampler - 传入组装方式:
collate_fn - 传入并行方式:
num_workers
2. 开始迭代(调用 next)¶
当 Python 执行 next(dataloader_iter) 时:
-
batch_sampler 提供索引
-
batch_sampler会决定一个 batch 要哪些样本。 -
如果你没传,默认逻辑是:
- 用
sampler生成单个索引(默认是range(len(dataset))或RandomSampler) - 再用
batch_size把索引打包成 batch。
- 用
🔎 举例:
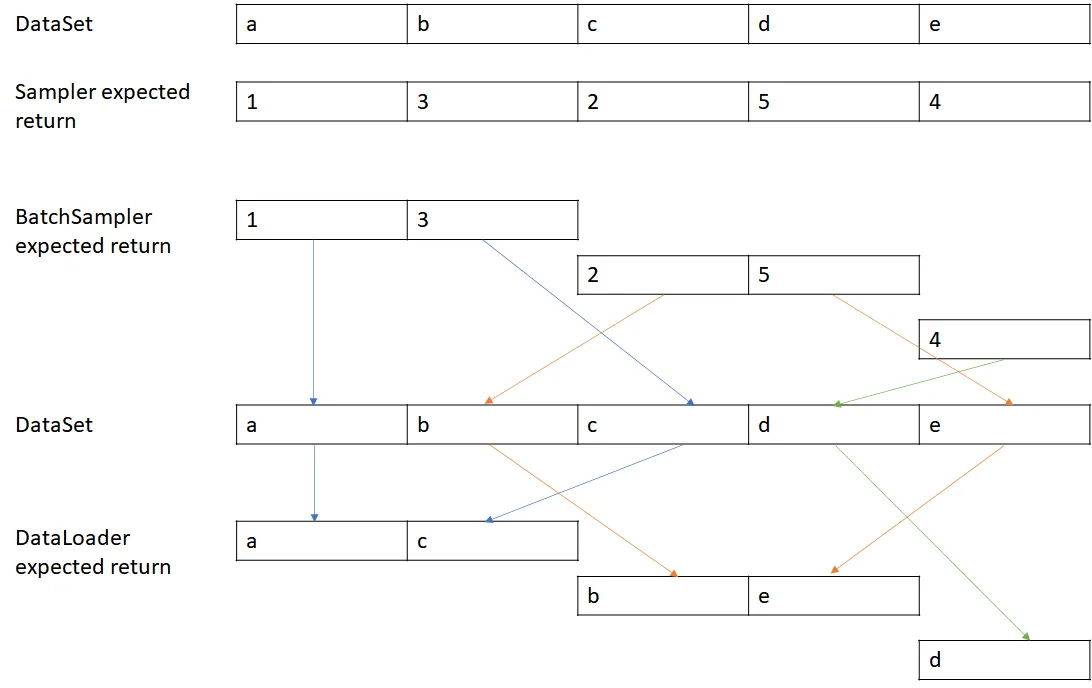
-
dataset.getitem 取出样本
-
DataLoader会根据batch_sampler给的索引列表[0,1,2,3] - 调用
dataset.__getitem__(i) - 得到一个个样本。
🔎 举例:
-
collate_fn 组装 batch
-
把
[dataset[i] for i in indices]的结果打包在一起。 - 默认行为是堆叠成张量(如果能堆叠),否则打包成 list。
- 如果你定义了
collate_fn,就在这里生效。
🔎 举例:
-
返回 batch
-
next(dataloader_iter)返回一个批次的数据(通常是张量或元组),交给训练循环。
3. dataset.len 的作用¶
-
在
sampler初始化时会用到: -
比如
RandomSampler(dataset)需要知道len(dataset)来决定总共多少个 index。 - 所以
__len__是必须实现的,除非你用的是 IterableDataset(流式数据)。
🔎 用一个小 demo 验证¶
from torch.utils.data import Dataset, DataLoader
class MyDataset(Dataset):
def __init__(self):
self.data = ["a", "b", "c", "d", "e"]
def __len__(self):
print(">>> __len__ called")
return len(self.data)
def __getitem__(self, idx):
print(f">>> __getitem__({idx}) called")
return self.data[idx]
def my_collate(batch):
print(f">>> collate_fn called with: {batch}")
return "-".join(batch)
loader = DataLoader(MyDataset(), batch_size=2, collate_fn=my_collate, shuffle=False)
for batch in loader:
print(f"Got batch: {batch}")
输出(核心流程你能清晰看到):
>>> __len__ called # 初始化 sampler 时
>>> __getitem__(0) called
>>> __getitem__(1) called
>>> collate_fn called with: ['a', 'b']
Got batch: a-b
>>> __getitem__(2) called
>>> __getitem__(3) called
>>> collate_fn called with: ['c', 'd']
Got batch: c-d
>>> __getitem__(4) called
>>> collate_fn called with: ['e']
Got batch: e
📌 总结执行顺序¶
当训练循环 next(dataloader_iter) 时,调用顺序是:
batch_sampler生成一批 index(依赖dataset.__len__)- 对每个 index 调用
dataset.__getitem__取出样本 - 调用
collate_fn把样本拼成 batch - 返回 batch 给训练循环
要不要我帮你画一张 流程图(Dataset → Sampler → BatchSampler → getitem → Collate_fn → Batch),这样你一眼就能看到 DataLoader 的工作顺序?
🔑 DataLoader 常用参数解析¶
torch.utils.data.DataLoader 的参数
DataLoader(
dataset,
pin_memory=pin_memory,
collate_fn=collate_fn,
worker_init_fn=get_seed_worker(seed),
num_workers=num_workers,
batch_sampler=batch_sampler,
prefetch_factor=prefetch_factor,
persistent_workers=persistent_workers
)
-
dataset
-
你的数据集对象,必须实现
__len__和__getitem__。 -
比如
torchvision.datasets.CIFAR10,或者你自己继承torch.utils.data.Dataset。 -
pin_memory
-
如果设为
True,DataLoader 会把张量放到 锁页内存 (pinned memory)。 - 好处:GPU 拷贝更快(减少 CPU→GPU 传输的瓶颈)。
-
常用于 训练时 GPU 加速。
-
collate_fn
-
重点 ⚡
- 作用:定义 如何把一个 batch 的样本拼在一起。
-
默认行为是把 dataset 返回的单个样本打包成一个 batch,例如:
* 你可以自定义,比如:- 处理不同长度的序列 → padding 对齐
- 处理 dict 类型样本
- 丢弃坏数据
- 例子:
-
worker_init_fn
-
每个
num_workers子进程初始化时会调用这个函数。 -
常用于 随机种子设置,保证数据加载可复现。
-
num_workers
-
启用多少个子进程来并行加载数据。
0表示用主进程加载(最安全,但慢)。-
大于 0 时可以大幅提升数据预处理速度(特别是 IO 瓶颈)。
-
batch_sampler
-
重点 ⚡
- 控制如何从 dataset 中采样 一个 batch 的 index。
- 和
sampler(单个样本采样器)不同,batch_sampler一次返回一个 batch 的 index 列表。 - 作用:完全接管 batch 的构造过程。
-
使用场景:
- 动态 batch size(比如按序列长度分组)
- 特殊采样策略(不规则 batch)
- 注意:设置了
batch_sampler,就不能再传batch_size和shuffle。
例子:
from torch.utils.data import BatchSampler, RandomSampler
sampler = RandomSampler(dataset)
batch_sampler = BatchSampler(sampler, batch_size=4, drop_last=False)
DataLoader(dataset, batch_sampler=batch_sampler)
-
prefetch_factor
-
每个 worker 预取多少个 batch,默认是
2。 -
增大能减少等待时间,但会占用更多内存。
-
persistent_workers
-
如果为
True,在 epoch 之间 保持 worker 存活,避免频繁 fork 子进程。 - 对大规模训练(多 epoch)提升效率明显。
📌 重点对比:collate_fn vs batch_sampler¶
batch_sampler:决定 抽哪些样本(index 层面)。 👉 控制“取哪些数据”。collate_fn:决定 怎么拼这些样本(数据拼接层面)。 👉 控制“如何组合成 batch”。
形象比喻:
batch_sampler= 菜市场采购单(告诉你买哪些菜)。collate_fn= 厨师拼盘(告诉你买来的菜怎么摆到一起)。
✅ 总结
collate_fn:把一个 batch 的数据 打包/对齐/拼接。batch_sampler:控制 采样逻辑,定义每个 batch 由哪些样本组成。
DataSet¶
ProcessorMixin¶
from transformers.processing_utils import ProcessorMixin 主要是引入 🤗 Transformers 库里的一个工具类,它的作用是为各种 Processor(处理器) 提供通用的功能。
在 Hugging Face 的生态里:
- Tokenizer:处理文本 → token id。
- Feature Extractor:处理音频、图像等输入 → 数值特征。
- Processor:是一个“打包器”,把 tokenizer + feature extractor 组合起来,对多模态任务(如语音识别、图像字幕生成)很方便。
🔎 ProcessorMixin 的作用¶
ProcessorMixin 是这些 Processor 类的基类,提供了统一的接口和通用逻辑,比如:
-
保存 & 加载
-
定义了
.save_pretrained()和.from_pretrained()方法 - 保证 processor 可以像模型一样保存到本地或从 Hub 加载
-
组件管理
-
Processor 里可能有 tokenizer、feature extractor、image processor 等
-
ProcessorMixin负责把这些组件的配置、权重组织在一起,保证保存/加载时一致 -
统一调用接口
-
Processor 本身可以像函数一样调用
- 内部会自动决定把输入送给 tokenizer 还是 feature extractor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
inputs = processor("some speech.wav", return_tensors="pt", sampling_rate=16000)
这里你不需要管用的是 tokenizer 还是 feature extractor,ProcessorMixin 把逻辑打通了。
📌 举个例子¶
以 Wav2Vec2Processor 为例:
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
print(processor.__class__.__mro__)
继承关系里就会看到 ProcessorMixin。
它让这个 processor 具备和模型/分词器一致的“预训练保存/加载”的体验。
✅ 总结:
ProcessorMixin 是 Hugging Face Transformers 里所有 Processor 类的基类,主要作用是:
- 提供保存/加载的标准方法
- 管理多个子组件(tokenizer / feature extractor 等)
- 统一调用接口,简化多模态处理
(图片)数据数据读取后处理¶
很棒的问题 👌 我帮你逐行拆解这段 prepare_images_input 代码,尤其是 images_spatial_crop 的作用。
📌 代码功能整体概览¶
这段函数的目标是:
👉 根据 images_spatial_crop 里提供的裁剪信息,从 images 中取出有效的图像 patch(tile),拼成一个批量输入给模型。
最终返回:
total_tiles:拼接后的所有 tile,形状[batch_all_tiles, 3, H, W](相当于把 batch 里每个样本有效的图像块统一拼接在一起)
📌 参数说明¶
- 输入的图像 tensor,一般形状是
[bs, max_num_tiles, 3, H, W] bs:batch sizemax_num_tiles:单个样本最多能有多少张图(tile)3, H, W:彩色图像通道、高度、宽度
- 输入的裁剪信息,形状
[bs, max_n_images, 2] - 每个元素是
(num_width_tiles, num_height_tiles),表示该图被切成多少块 - 注意:当
(0, 0)时,说明没有更多有效图像(提前结束)
📌 核心逻辑分解¶
1. 判空¶
- 如果
images没有传,或者所有裁剪信息都是 0(即没有 tile),直接返回None。
2. 获取 batch 维度¶
bs, max_n_images, _ = images_spatial_crop.shape
batch_num_tiles = [0 for _ in range(bs)]
total_tiles = []
bs:批大小max_n_images:每个样本最多能有多少张原始图像batch_num_tiles:记录每个样本里 tile 的总数total_tiles:用来存放每个样本的有效 tile
3. 遍历 batch¶
for idx in range(bs):
for jdx in range(max_n_images):
num_width_tiles, num_height_tiles = images_spatial_crop[idx, jdx]
if num_width_tiles == 0 or num_height_tiles == 0:
break
batch_num_tiles[idx] += (1 + num_width_tiles * num_height_tiles)
对每个样本 (idx):
- 遍历该样本的多张图像 (
jdx) -
取出
(num_width_tiles, num_height_tiles) -
如果是
(0,0),说明没图了 → 提前退出循环 -
否则计算 tile 数:
-
1:原图 num_width_tiles * num_height_tiles:切出来的 patch 数- 累加到
batch_num_tiles[idx]
👉 举个例子:
如果 images_spatial_crop[idx, jdx] = (2, 2):
- tile 数 =
1 + 2*2 = 5 - 表示:原图 + 4 个裁剪 patch
4. 收集有效 tile¶
- 从
images[idx]中取前batch_num_tiles[idx]张图 - 丢到
total_tiles列表
5. 拼接所有 batch¶
- 把所有 batch 的 tile 拼接成一个大张量
- 形状
[batch_all_tiles, 3, H, W]
6. 检查¶
if total_tiles.shape[0] != sum(batch_num_tiles):
raise AssertionError
if total_tiles.shape[0] == 0:
return None
- 保证拼接后的 tile 数和统计的总 tile 数一致
- 如果 tile 数为 0 → 返回
None
📌 总结¶
images:存放所有原始图像和裁剪 patch-
images_spatial_crop:记录每张图的裁剪情况(num_width_tiles, num_height_tiles) -
(0,0)表示没有更多有效图 (2,2)表示切成 2×2 个小块,加上原图,总共 5 张
最终返回:
一个 [batch_all_tiles, 3, H, W] 的 tensor,把 batch 里所有有效 tile 拼起来。
要不要我帮你画一张 图示(原图 → tile → batch 拼接),更直观地展示 images_spatial_crop 是怎么控制裁剪和拼接的?