NPU Training Operators - GMM
导言
GMM 在 Qwen3.5 MoE 里的接入点是 routed experts 的两次矩阵乘:hidden -> gate/up 和 intermediate -> hidden。shared_expert 仍是普通 Qwen3_5MoeMLP,attention 不动,Dense 版 Qwen3.5 的普通 MLP 也不是替换对象。
PR #2664 的公开 diff 主要是给 mindspeed_mm.fsdp.ops.moe_ops.gemm.grouped_matmul 增加 fused/eager 一致性 UT,并放宽 unpermute UT 容差;它可以作为 GMM wrapper 接口被测试覆盖的证据,不能写成完整功能接入 PR。12
结论¶
- PR 状态:MindSpeed-MM PR #2664
test: add grouped_matmul fused vs eager consistency test已于 2026-06-09 17:05:48 合入;公开 diff 新增tests/ut_fsdp/ops/moe_ops/test_gemm.py,并把test_unpermute.py的atol从1e-3放宽到1e-2。12 - 算子对象:
grouped_matmul(x, weight, group_list, fused=True)在 NPU 上调用torch_npu.npu_grouped_matmul;CPU/非 NPU 路径回退到按 group 循环torch.matmul。3 - 模型对象:Qwen3.5 MoE 中
Qwen3_5MoeExperts的gate_up_proj[num_experts, hidden, 2 * intermediate]和down_proj[num_experts, intermediate, hidden]是 GMM 权重;Qwen3_5MoeSparseMoeBlock.shared_expert是Qwen3_5MoeMLP,不走 GMM。5 - 配置对象:Qwen3.5-397B 配置启用
model_id: qwen3_5_moe、expert_parallel_size: 16、ep_plan.apply_modules: model.language_model.layers.{*}.mlp.experts、use_grouped_expert_matmul: true。6 - 验证对象:PR #2664 的 UT 覆盖 4 组 shape:均匀分组、不均匀分组、小维度升维、4 expert 等分;输入和权重使用
bfloat16,fused/eager 输出用rtol=1e-2, atol=1e-2比较。4
算子语义¶
先把 GMM 看成批处理 for-loop
routed expert 的朴素写法是:按 expert 找到自己的 token,循环执行 token_slice @ expert_weight,再把结果写回原 token 位置。GMM 做的是同一件事,只是要求 token 已经按 expert 连续排好,然后把多个 expert 的小 GEMM 一次交给 NPU fused kernel。
普通 eager 路径可以写成下面的形态:
start = 0
for expert_id, token_count in enumerate(group_list):
end = start + token_count
output[start:end] = x[start:end] @ weight[expert_id]
start = end
GMM fused 路径把这段循环交给 torch_npu.npu_grouped_matmul。它仍然需要同样的信息:
| 输入 | 例子 | 含义 |
|---|---|---|
x |
[sum(group_list), hidden] |
已按 expert 连续排列的 token buffer。 |
weight |
[num_experts, hidden, out] |
每个 expert 一份权重。 |
group_list |
[1, 2, 0, 2] |
第 0 个 expert 吃 1 行,第 1 个吃 2 行,第 2 个空桶,第 3 个吃 2 行。 |
一个具体例子:
原 token-expert 对:
(t0, E1), (t0, E3), (t1, E1), (t2, E0), (t3, E3)
permute 后:
E0: [t2] -> 1 行
E1: [t0, t1] -> 2 行
E2: [] -> 0 行
E3: [t0, t3] -> 2 行
group_list = [1, 2, 0, 2]
这时 GMM 的 row-to-weight 映射是:
x 行范围 |
使用权重 | 说明 |
|---|---|---|
0:1 |
weight[0] |
E0 的 1 个 token。 |
1:3 |
weight[1] |
E1 的 2 个 token。 |
3:3 |
weight[2] |
E2 空桶,不能破坏后续 offset。 |
3:5 |
weight[3] |
E3 的 2 个 token。 |
group_list 是 GMM 的控制面。它必须和 permute 后的 token 排列一致,否则 fused GMM 会把某个 expert 的 token 乘到另一个 expert 的权重上。mindspeed_mm.fsdp.ops.moe_ops.gemm.eager_grouped_matmul 用 torch.cumsum(group_list) 得到每个 expert 的 [start, end) 区间;NPU fused 路径把同一个 group_list 传给 torch_npu.npu_grouped_matmul,并设置 split_item=2, group_type=0, group_list_type=1。3
反向也遵循同一个分组边界,不是把所有 token 当成一个普通 GEMM:
- 输入梯度:
grad_input_e = grad_output_e @ W_e^T,代码里先torch.transpose(weight, 1, 2),再用split_item=2, group_type=0。 - 权重梯度:
grad_weight_e = X_e^T @ grad_output_e,代码里用input_tensor.T和split_item=3, group_type=2。
这说明 GMM 迁移不能只看前向吞吐;必须同时看 grad_input、grad_weight、expert 空桶、BF16 容差和 group_list 数据类型。
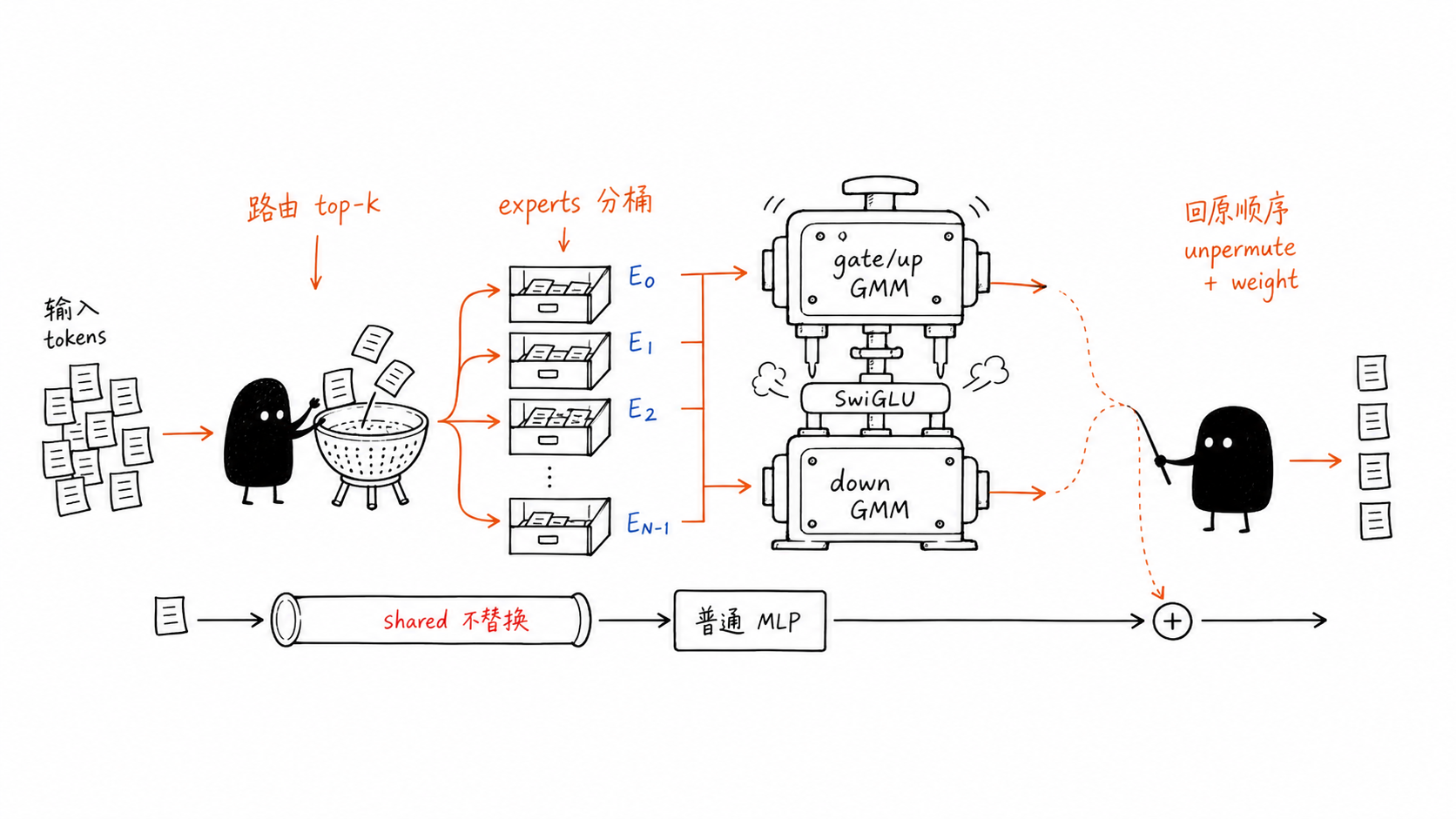
Qwen3.5 MoE 路径¶
Qwen3.5 MoE block 分成两条路径:
- shared expert:
Qwen3_5MoeMLP仍然是三段 dense linear:gate_proj、up_proj、down_proj。它对所有 token 都执行,最后经过shared_expert_gate缩放后加到 expert 输出上。5 - routed experts:
Qwen3_5MoeTopKRouter对 token 计算 router logits,torch.topk选 expert,Qwen3_5MoeExperts根据top_k_index和top_k_weights执行专家计算。5
启用 use_grouped_expert_matmul 且 NPU 可用时,routed experts 的本地路径是:
hidden_states
-> router top-k
-> npu_moe_token_permute(selected_experts)
-> tokens_per_expert = histc(selected_experts)
-> npu_group_gemm(gate_up_proj)
-> npu_swiglu
-> npu_group_gemm(down_proj)
-> npu_moe_token_unpermute(row_ids_map, probs=routing_weights)
其中两次 GMM 对应:
| 段 | 输入 | 权重 | 输出 | 说明 |
|---|---|---|---|---|
gate/up GMM |
[sum(T_e), hidden] |
[num_experts, hidden, 2 * intermediate] |
[sum(T_e), 2 * intermediate] |
一次 GMM 同时算 gate 和 up,随后 SwiGLU split。 |
down GMM |
[sum(T_e), intermediate] |
[num_experts, intermediate, hidden] |
[sum(T_e), hidden] |
每个 expert 的 down projection 独立计算,再 unpermute 回原 token。 |
这条路径的关键边界是 只替换 routed expert 的专家矩阵乘。如果把 Dense MLP、shared expert 或 attention 写进迁移范围,会导致测试对象错位:Dense MLP 没有 group_list,shared expert 没有 top-k expert bucket,attention 的主算子约束也不是 expert-wise grouped GEMM。
EP 里怎么用¶
EP 场景里,GMM 不负责跨卡搬 token。跨卡搬运由 alltoall dispatcher 完成;GMM 只处理当前 rank 收到的本地 expert token。
router top-k
-> 生成全局 expert id
-> 按 expert owner rank 做 AllToAll dispatch
-> 每个 EP rank 收到自己负责的 expert token
-> 本 rank 内按 local expert 生成 group_list
-> gate/up GMM
-> SwiGLU
-> down GMM
-> AllToAll combine / unpermute 回原 token 顺序
对应到 Qwen3.5-397B 配置,expert_parallel_size: 16 表示 routed experts 分给 16 个 EP rank;ep_plan.apply_modules 只匹配 model.language_model.layers.{*}.mlp.experts,所以 shared_expert 不进入 EP expert shard,也不进入 GMM 替换范围。6
不要把 GMM 和 EP dispatcher 混成一个概念
use_grouped_expert_matmul: true 只说明 expert 内部矩阵乘使用 grouped matmul。ep_plan.dispatcher: alltoall 说明 token 如何在 EP rank 间交换。前者是计算算子,后者是通信路径;只有 MC2 才把通信和 grouped matmul 合成 fused 段。
与 MC2 区分¶
GMM 和 MC2 不是同一个层级:
- GMM 解决本 rank 内或本地 expert shard 上的多 expert 矩阵乘批处理问题,核心输入是
X、3D expert weight 和tokens_per_expert。 - EP alltoall 解决 token 在 expert parallel ranks 之间的 dispatch/combine 问题,核心输入是
selected_experts、send_counts、recv_counts和ep_group。 - MC2 把 EP 场景里相邻的
AllToAllv + GroupedMatmul或GroupedMatmul + AllToAllv合成 fused 段,核心依赖 HCCL comm name、count list 和 expert weight shard。
所以迁移顺序应当是:
- 先让非 EP 或本地 expert 的
grouped_matmul和 eager 路径对齐。 - 再让 EP
alltoall路径下的 routed experts 输出和非 fused baseline 对齐。 - 最后再考虑 MC2,把通信和 GMM 合成一个 fused 段。
接入方案¶
最小接入条件:
config.use_grouped_expert_matmul = true。- 模型是 MoE,且专家权重是 3D tensor:
[num_experts, in_dim, out_dim]。 selected_experts的范围在[0, num_experts)。- token 已经按 expert 连续排列,
group_list.sum() == permuted_tokens.shape[0]。 group_list和 fused op 约束一致;PR #2664 的 UT 使用torch.tensor(group_sizes, device=device),测试 BF16 输入和 BF16 权重。4
Qwen3.5-397B 的配置入口如下:
parallel:
expert_parallel_size: 16
ep_plan:
apply_modules:
- model.language_model.layers.{*}.mlp.experts
dispatcher: alltoall
model:
model_id: qwen3_5_moe
use_grouped_expert_matmul: true
这里 ep_plan.apply_modules 只指向 mlp.experts,没有指向 mlp.shared_expert、attention 或 Dense MLP。dispatcher: alltoall 说明这份配置启用的是 MoE/EP 路径;是否使用 MC2 需要另行切到 MC2 dispatcher,并验证 use_npu_fused_ops、HCCL group 和 count list。
验证项¶
| 类型 | 检查项 | 失败信号 |
|---|---|---|
| Shape | group_list.sum()、permute 后 token 数、两次 GMM 输出 shape、unpermute 后 [tokens, hidden]。 |
某个 expert token 数越界,或 down GMM 输出无法还原原 token 顺序。 |
| 数值 | 同一输入下比较 grouped_matmul(fused=True) 与 fused=False;BF16 可先沿用 PR #2664 的 rtol=1e-2, atol=1e-2。 |
单 expert 或不均匀 group 下 diff 放大。 |
| 反向 | 检查 grad_input、grad_weight,尤其是空 expert、不均匀 expert 和 top-k 重复 token。 |
某些 expert 梯度为 0,或权重梯度 shape 与 3D 权重不一致。 |
| 路由 | tokens_per_expert、router top-k 分布、routing weights 归一化。 |
少数 expert 过载,或 top-k 结果与 unpermute 权重不匹配。 |
| 性能 | GMM time、permute/unpermute time、host time、NPU util。 | GMM 变快但 permute/host 开销吃掉收益。 |
| 回退 | 保留 eager/非 fused 路径,配置可关闭 use_grouped_expert_matmul。 |
无法快速定位是 GMM、路由还是 EP 通信问题。 |
论文证据¶
GMM 的系统动机来自 MoE 的动态专家分组。GShard 把 MoE 层拆成 gating、dispatch、expert compute、combine;Tutel 强调 token routing 会在运行时改变 expert workload;MegaBlocks 进一步指出现有 MoE 系统常在 drop token 和 padding 之间取舍,并用 block-sparse 计算处理动态 expert token 分布。789
MegaBlocks 摘要还给出端到端训练结果:相对 Tutel 最高 40% speedup,相对 Megatron-LM 最高 2.4x。这个结果只能证明“动态专家分组计算值得优化”,不能直接外推到 MindSpeed-MM 的 torch_npu.npu_grouped_matmul。NPU 侧仍要以同一模型、同一 EP size、同一 batch/seq 配置下的 profiler 和 loss 对齐为准。9
风险¶
- 范围误判:GMM 只替换 routed experts 的两次矩阵乘;把 shared expert、Dense MLP 或 attention 纳入替换范围会让验证对象错误。
- 计数错误:
tokens_per_expert是分组边界,错一个 token 就会造成 expert 权重错配。 - 空桶风险:真实 MoE 路由可能出现空 expert 或极端不均匀 expert,PR #2664 的 UT 还没有覆盖空 group。
- 反向风险:PR #2664 公开测试主要比较 fused/eager 前向输出;迁移时要补
grad_input、grad_weight和短训 loss。 - 性能风险:小 batch、低 top-k、expert token 太少时,GMM launch/permute/unpermute 可能抵消 fused GEMM 收益。
- 版本风险:
torch_npu.npu_grouped_matmul不是 PyTorch 通用 API,split_item、group_type、group_list_type的语义需要和目标 CANN / torch_npu 版本一起确认。
实测表模板¶
| Case | eager | fused GMM | 备注 |
|---|---|---|---|
grouped_matmul max abs diff |
待测 | 待测 | 固定 seed,覆盖均匀/不均匀/空 expert。 |
| routed expert output diff | 待测 | 待测 | shared_expert 单独固定,避免混入 dense 路径差异。 |
grad_input diff |
待测 | 待测 | 对齐 BF16 容差。 |
grad_weight diff |
待测 | 待测 | 按 expert 统计,检查空桶和小桶。 |
| GMM time | 待测 | 待测 | profiler 只看两次 expert matmul。 |
| permute/unpermute time | 待测 | 待测 | 判断 token 重排是否成为瓶颈。 |
| step time | 待测 | 待测 | 端到端收益必须用完整训练 step 判断。 |