NPU Training Operators - RoPE MRoPE
导言
MindSpeed core_r0.16.0 的 --use-fused-rotary-pos-emb 是普通 RoPE 路径:freqs -> cos/sin -> npu_rotary_position_embedding(x, cos, sin, mode)。torch_npu 另有 npu_rotary_mul、npu_interleave_rope、npu_mrope,其中 npu_mrope 可以覆盖推理侧多模态 MRoPE;这和 Megatron Bridge 的 config.apply_rope_fusion 不是同一个开关。
客户报错 Qwen3VLMultimodalRotaryEmbedding has no attribute get_rotary_seq_len 的直接含义是:Qwen3-VL 的 MRoPE 对象被送进了 Megatron Core 的普通 rope 分支。先修正分支:position_embedding_type="mrope",apply_rope_fusion=False。如果要用 NPU MRoPE fused,应在 q/k rotary apply 处显式接 torch_npu.npu_mrope,不是打开普通 apply_rope_fusion。
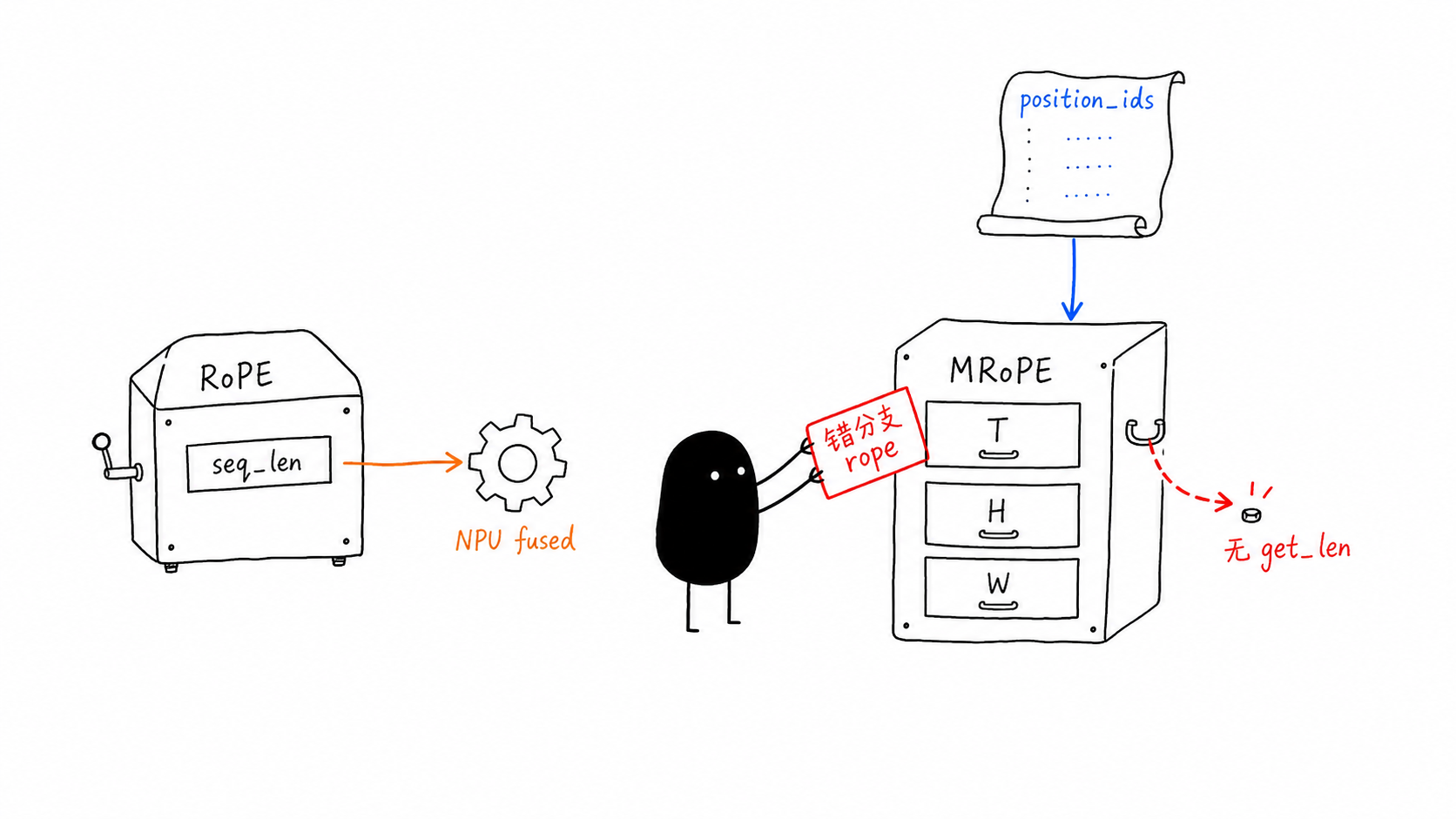
结论¶
- 普通 NPU RoPE 可以接:MindSpeed patch
rope_utils.apply_rotary_pos_emb,当args.use_fused_rotary_pos_emb=True时调用mindspeed.ops.npu_rotary_position_embedding.npu_rotary_position_embedding,底层 C++ 绑定aclnnRotaryPositionEmbedding。9 10 - Qwen3-VL MRoPE 不是不能用 NPU fused:不能直接开的只是 Bridge/MCore 的
config.apply_rope_fusion普通 RoPE 分支;可用路径是把 q/k 展平成torch_npu.npu_mrope要求的二维 token-major 形态,并传入positions、cos_sin_cache、head_size、mrope_section。7 npu_rotary_mul和npu_interleave_rope不是 MRoPE 替代品:前者是通用 RoPE elementwise fused,支持rotary_mode='half'/'interleave';后者是推理图模式友好的固定 BNSD interleave RoPE,D=64、cos/sin的N=1。5 6- MindSpeed 与 MindSpeed-MM 的路径不同:MindSpeed core 用
npu_rotary_position_embedding做普通 RoPE;MindSpeed-MM 的 FSDP/HF 模型通常先用 Python 构造 MRoPE 的cos/sin,再用npu_rotary_mul做 q/k 旋转;verl/vLLM 推理路径才会出现npu_mrope。 - Qwen3-VL 不要直接开 MindSpeed 普通 fused RoPE:MindSpeed 参数校验要求
--use-fused-rotary-pos-emb必须配--position-embedding-type=rope。MRoPE 的合法入口是position_embedding_type="mrope"。8 - 客户栈的错误是配置/接口合同错位:Megatron Core 0.16.1 的
rope分支会调用self.rotary_pos_emb.get_rotary_seq_len(...);Qwen3-VL 的Qwen3VLMultimodalRotaryEmbedding.forward(...)只接收position_ids、mrope_section、packed_seq_params。17 20 - 最小修复:构建 Qwen3-VL 语言模型前确认
language_transformer_config.position_embedding_type = "mrope",mrope_section = [24, 20, 20],apply_rope_fusion = False,并不要设置 MindSpeed--use-fused-rotary-pos-emb。 - 融合接入点:
apply_rotary_pos_emb_absolute现在逐个处理query、key,并且代码里有assert not config.apply_rope_fusion;NPU MRoPE fused 应新增独立分支,一次性处理 q/k,而不是改这个 assert 为 true。15 - 训练边界要单独验:
npu_rotary_mul文档说明训练正向会保留input供反向计算;npu_mrope文档写的是推理场景。Qwen3-VL 训练若要替换成npu_mrope,必须先验证 autograd/反向或保留 unfused backward;verl/vLLM rollout 则天然是推理路径。5 7
RoPE 算子路径¶
RoPE 的计算对象是 attention 里的 query 和 key。RoFormer 论文定义的是按位置构造旋转矩阵,使绝对位置进入 q/k,同时在内积里体现相对位置信息。1 Megatron Core 的普通路径把这个过程拆成两步:
RotaryEmbedding.get_rotary_seq_len(...)根据 inference、packed sequence、sequence parallel、context parallel 计算需要的rotary_seq_len。18RotaryEmbedding.forward(rotary_seq_len, ...)生成freqs,attention 再调用apply_rotary_pos_emb(query/key, freqs, config, ...)。
MindSpeed core_r0.16.0 的 fused RoPE 只替换第二步里的逐元素旋转:
cos_ = torch.cos(freqs).to(t.dtype)
sin_ = torch.sin(freqs).to(t.dtype)
mode = 1 if rotary_interleaved else 0
t = npu_rotary_position_embedding(t.contiguous(), cos_, sin_, mode).to(t.dtype)
底层 C++ 绑定说明 mode 0 是 GPT-NeoX style,mode 1 是 GPT-J style。10 因此普通接入条件很具体:
position_embedding_type == "rope"。args.use_fused_rotary_pos_emb == True。freqs可以由单一rotary_seq_len生成。rotary_interleaved只影响mode,不改变接口形态。- 需要
torch_npu/ CANN 环境能加载npu_rotary_position_embedding扩展。
NPU 融合算子¶
npu_rotary_mul¶
torch_npu.npu_rotary_mul(input, r1, r2, rotary_mode='half', rotate=None) 计算:
这里 r1 是 cos,r2 是 sin。rotary_mode 决定 rotate(input) 的布局:
half/ GPT-NeoX style:x1, x2 = chunk(x, 2, dim=-1),rotate(x) = concat(-x2, x1)。interleave/ GPT-J style:x1 = x[..., ::2],x2 = x[..., 1::2],rotate(x)按(-x2, x1)交错写回。
它适合替换 Python 里的 (x * cos) + (rotate_half(x) * sin)。MindSpeed-MM 的 FSDP Qwen3.5 MoE 文本 attention 已经这么写:先按 cos.shape[-1] 切出 q_rot/k_rot,NPU 上调用 torch_npu.npu_rotary_mul(q_rot, cos, sin),再把 q_pass/k_pass 拼回去。11 GLM4V vision encoder 还显式传 rotary_mode='interleave'。12
npu_interleave_rope¶
torch_npu.npu_interleave_rope(x, cos, sin) 是更窄的 interleave RoPE 接口:x/cos/sin 都是四维 B, N, S, D,只支持推理场景、图模式、D=64,并要求 cos/sin 的 N=1。6
它的数学核心仍是:
但接口语义固定为 interleave RoPE 的推理形态,不处理 positions 查表,也不处理三轴 MRoPE 的 mrope_section。训练侧一般先看 npu_rotary_mul,推理侧再看 npu_mrope;不要把这个算子当成 Qwen3-VL MRoPE 的直接落点。
npu_mrope¶
torch_npu.npu_mrope(positions, query, key, cos_sin_cache, head_size, *, mrope_section=None, rotary_mode='half', cache_mode='default') -> (query_out, key_out) 是推理场景下的 q/k fused RoPE/MRoPE。7 它和 npu_rotary_mul 的差异是:npu_mrope 负责 按 positions 从 cache 取 cos/sin,并一次处理 query 和 key。因此它很适合 vLLM/verl rollout;如果放进训练 forward,需要先确认反向是否由当前 torch_npu 版本支持。
普通 RoPE 模式:
positions.shape == (num_tokens,)。mrope_section不传或[0, 0, 0]。cos_sin_cache.shape == (max_seq_len, rotary_dim),最后一维chunk(2)得到cos/sin。
MRoPE 模式:
positions.shape == (3, num_tokens)或(4, num_tokens),行数必须和mrope_section段数一致。mrope_section的元素和等于rotary_dim / 2。例如 Qwen3-VL 常见[24, 20, 20],Qwen3.5 MoE 配置里可见[11, 11, 10]。query/key是二维(num_tokens, num_heads * head_size),不是 Bridge attention 内部常见的 BSHD/THD 四维张量。
cache_mode='default' 和 cache_mode='interleave' 的差异在 cos/sin 拼接方式:
default:按段取值并拼接。三段时近似是cat(cos_t[:t], cos_h[t:t+h], cos_w[t+h:t+h+w]);四段时按mrope_section拆分后取对应行再拼回。interleave:不是把 t/h/w 三段连续拼起来,而是在半维度内按 stride 写回 H/W 位置。官方公式是把cos[..., 1:h*3:3]换成 H 轴、cos[..., 2:h*3:3]换成 W 轴,sin同理。MindSpeed-MM 的 Qwen3.5/Qwen3-VL 实现也采用这个思路:从 T 轴频率开始,H 写入slice(1, h*3, 3),W 写入slice(2, w*3, 3)。14
rotary_mode 再决定每个二维旋转平面怎么取:half 是 [前半维, 后半维] 成对旋转,interleaved 是 [偶数维, 奇数维] 成对旋转。cache_mode 解决 MRoPE 三轴如何排布,rotary_mode 解决单个 RoPE 旋转对如何排布,两者不是一个概念。
MRoPE 差异¶
Qwen2-VL 论文把 M-RoPE 描述为融合 text、image、video 位置信息的机制;它不是单轴 token 序号,而是同时编码 temporal、height、width。2 Qwen2.5-VL 继续强调动态分辨率和视频时间编码;Qwen3-VL 的公开技术报告提供模型背景,但本文的接口判断以 Megatron Bridge 0.4.0 源码为准。3 4
Megatron Core 0.16.1 的 MultimodalRotaryEmbedding.forward 接口是:
rotary_pos_emb = self.rotary_pos_emb(
position_ids,
self.mrope_section,
cp_group=packed_seq_params.cp_group if packed_seq_params is not None else None,
)
position_ids 的 shape 是 [3, batch, seqlen],mrope_section 决定 head_dim 中 temporal / height / width 三段怎么切。Qwen3-VL Bridge 0.4.0 又实现了专用 Qwen3VLMultimodalRotaryEmbedding:它把三轴 freqs 重新组织成交错布局,并且文档明确 forward(position_ids, mrope_section, packed_seq_params),没有 get_rotary_seq_len 方法。20
这意味着 MRoPE 的控制面是 position_ids,不是 seq_len。对 Qwen3-VL 来说,get_rope_index(...) 会根据 input_ids、image_grid_thw、video_grid_thw 生成位置;packed sequence 时还会把 position_ids 转成 THD 格式,并设置 rotary_pos_emb.is_thd_format = True,避免 CP 下重复切分。22
MindSpeed-MM 的 Qwen3.5/Qwen3-VL MRoPE 还有一个容易误解的点:apply_interleaved_mrope 处理的是 MRoPE 频率表的 T/H/W 交错布局,不是普通 RoPE 的 rotary_interleaved=True。普通 rotary_interleaved 只改变最后一维里的旋转配对方式;MRoPE interleaved 会先根据三轴 position_ids 分别生成 freqs[0/1/2],再把 H/W 的频率按 1::3、2::3 写回 T 基准频率。14
MindSpeed-MM 关键代码¶
MindSpeed-MM 的 Qwen3.5 MoE FSDP 路径不是直接把三轴 MRoPE 丢给 npu_rotary_mul。第一步先根据 position_ids 生成三轴频率,并把 H/W 频率写入交错位置。14
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(2, 3)
freqs = self.apply_interleaved_mrope(freqs, self.mrope_section)
emb = torch.cat((freqs, freqs), dim=-1)
cos = emb.cos() * self.attention_scaling
sin = emb.sin() * self.attention_scaling
def apply_interleaved_mrope(self, freqs, mrope_section):
freqs_t = freqs[0]
for dim, offset in enumerate((1, 2), start=1):
length = mrope_section[dim] * 3
idx = slice(offset, length, 3)
freqs_t[..., idx] = freqs[dim, ..., idx]
return freqs_t
第二步才是普通 q/k RoPE apply:按 rotary_dim 切出参与旋转的前缀,NPU 上用 npu_rotary_mul 替换 (x * cos) + rotate_half(x) * sin,最后把不旋转的后缀拼回去。11
cos = cos.unsqueeze(unsqueeze_dim)
sin = sin.unsqueeze(unsqueeze_dim)
rotary_dim = cos.shape[-1]
q_rot, q_pass = q[..., :rotary_dim], q[..., rotary_dim:]
k_rot, k_pass = k[..., :rotary_dim], k[..., rotary_dim:]
if IS_NPU_AVAILABLE:
q_embed = torch_npu.npu_rotary_mul(q_rot, cos, sin)
k_embed = torch_npu.npu_rotary_mul(k_rot, cos, sin)
else:
q_embed = (q_rot * cos) + (rotate_half(q_rot) * sin)
k_embed = (k_rot * cos) + (rotate_half(k_rot) * sin)
q_embed = torch.cat([q_embed, q_pass], dim=-1)
k_embed = torch.cat([k_embed, k_pass], dim=-1)
所以更精确的描述是:MindSpeed-MM 用 Python 构造 MRoPE 的三轴 cos/sin 布局,再用 npu_rotary_mul 加速最后的 RoPE 旋转。npu_rotary_mul 本身不知道 temporal/height/width,它只消费已经排好的 cos/sin。
报错根因¶
客户栈:
MindSpeed: core_r0.16.0
Megatron Core: 0.16.1
AttributeError: 'Qwen3VLMultimodalRotaryEmbedding' object has no attribute 'get_rotary_seq_len'
从 traceback 可定位到 Megatron Core GPTModel._preprocess 的普通 rope 分支:
if self.position_embedding_type == "rope":
rotary_seq_len = self.rotary_pos_emb.get_rotary_seq_len(...)
rotary_pos_emb = self.rotary_pos_emb(rotary_seq_len, ...)
elif self.position_embedding_type == "mrope":
rotary_pos_emb = self.rotary_pos_emb(position_ids, self.mrope_section, ...)
因此可以做一个直接判断:只要代码调用了 get_rotary_seq_len,当时 self.position_embedding_type 就是 "rope",不是 "mrope"。
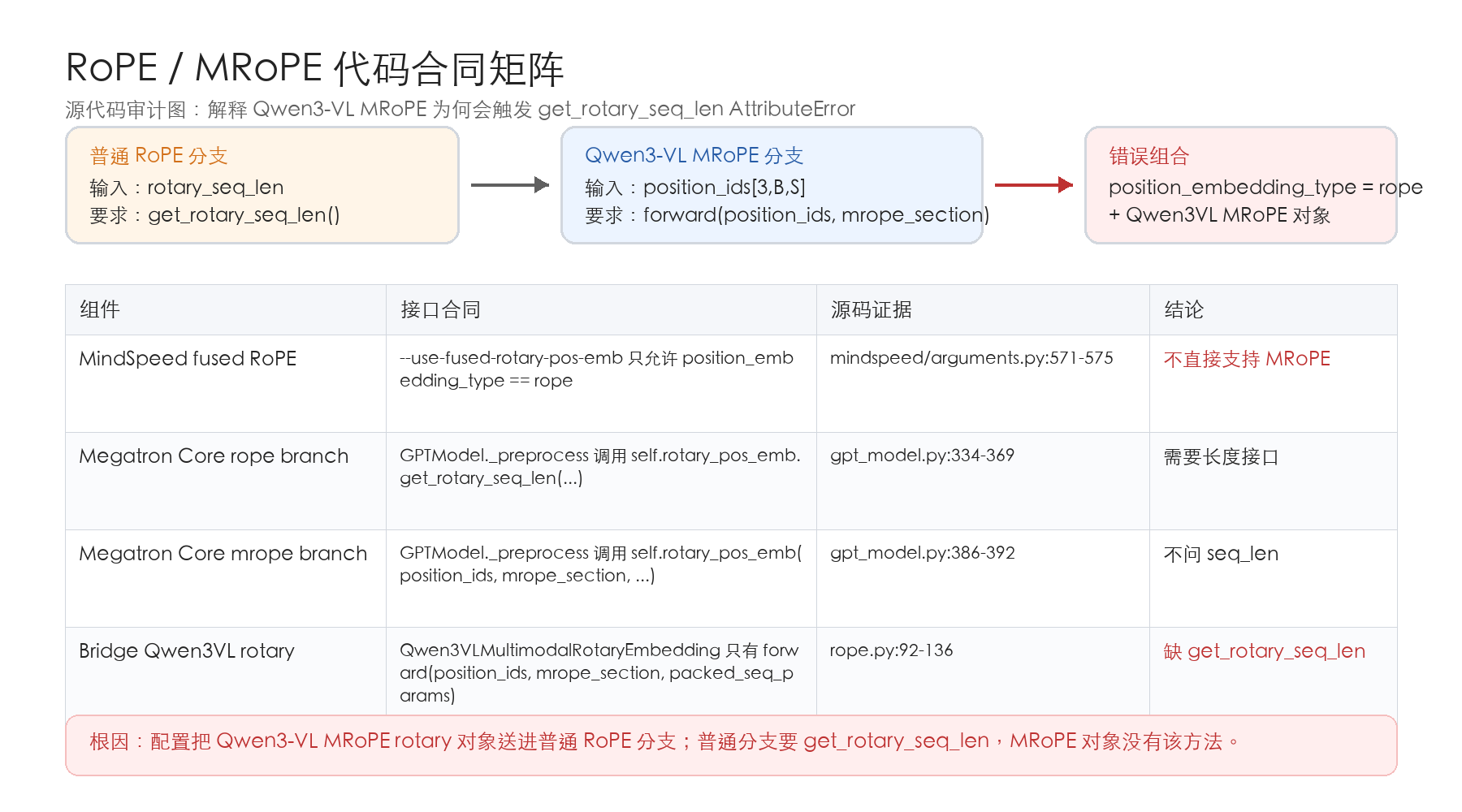
Megatron Bridge 0.4.0 的 Qwen3VLGPTModel.__init__ 会先调用 super().__init__(position_embedding_type=position_embedding_type, ...),再把 self.rotary_pos_emb 重建成 Qwen3VLMultimodalRotaryEmbedding。21 这里有一个版本兼容坑:Megatron Core GPTModel.__init__ 优先读 self.config.position_embedding_type,只有 config 没有该字段时才使用构造参数。16
所以错误组合是:
- 配置合并或训练参数把
language_transformer_config.position_embedding_type设成了"rope"。 Qwen3VLGPTModel又把self.rotary_pos_emb重建成 Qwen3-VL MRoPE 对象。_preprocess按"rope"分支执行,要求get_rotary_seq_len。- MRoPE 对象只有
forward(position_ids, mrope_section, packed_seq_params),于是报 AttributeError。
这个错误通常不是因为 torch_npu 没装、CANN op 缺失或 attention kernel 不支持,而是 Qwen3-VL MRoPE 的配置被普通 RoPE fused 需求污染了。
接入方案¶
普通 RoPE¶
适用:Llama/Qwen text-only、position id 是单轴序列长度、Megatron Core 使用普通 RotaryEmbedding。
配置形态:
检查项:
args.position_embedding_type == "rope",否则 MindSpeed 会在参数校验阶段抛错。config.apply_rope_fusion与 MindSpeed patch 不要互相覆盖;MindSpeed 的 NPU fused 路径是args.use_fused_rotary_pos_emb控制。- profiler 中应能看到 NPU rotary op,且普通 unfused 路径可回退。
MindSpeed-MM 的 FSDP HuggingFace 风格模型没有走 MindSpeed npu_rotary_position_embedding 扩展,而是在模型文件里直接调用 torch_npu.npu_rotary_mul。Qwen3.5 MoE 的 text attention 和 vision attention 都是这种写法:q_rot/k_rot -> npu_rotary_mul -> cat(pass)。11
Qwen3-VL MRoPE¶
适用:Qwen3-VL / Qwen3.5-VL 这类 position_ids[3, B, S] 多模态位置编码。
构建模型前强制检查:
language_transformer_config.position_embedding_type = "mrope"
language_transformer_config.mrope_section = [24, 20, 20]
language_transformer_config.apply_rope_fusion = False
args.use_fused_rotary_pos_emb = False
如果当前封装仍会被外层参数覆盖,可以在 Qwen3VLGPTModel.__init__ 里加防御断言:
临时止血可以在 super().__init__(...) 之后、forward 之前设置:
但这只能修正 Python 分支,不等于启用 NPU fused MRoPE。要做真正的 NPU MRoPE fused,需要新增一个 MRoPE-aware 路径,核心是把 Bridge 的 BSHD/THD 张量适配到 npu_mrope 的二维 token-major 接口:
# 伪代码:具体 permute/reshape 取决于当前 attention 内 query/key layout。
positions_2d = position_ids.reshape(3, -1).contiguous()
q_2d = query.reshape(num_tokens, num_q_heads * head_size).contiguous()
k_2d = key.reshape(num_tokens, num_kv_heads * head_size).contiguous()
q_out, k_out = torch_npu.npu_mrope(
positions_2d,
q_2d,
k_2d,
cos_sin_cache,
head_size,
mrope_section=config.mrope_section,
rotary_mode="half",
cache_mode="interleave",
)
接入顺序:
- 先修分支:
position_embedding_type="mrope",并保留apply_rope_fusion=False,否则 v0.4.0 的apply_rotary_pos_emb_absolute会直接 assert。15 - 再接 fused q/k:在 attention 已经拿到
query/key、position_ids或等价位置信息后,新增torch_npu.npu_mrope分支。 - 适配 layout:
npu_mrope接口是(num_tokens, num_heads * head_size);Bridge BSHD 要 flattenB*S,THD 要沿 packed token 维保持cu_seqlens对齐。 - 选择 cache_mode:Qwen3-VL/Qwen3.5 的
apply_interleaved_mrope等价于cache_mode='interleave'的三轴交错语义;四段[16, 16, 16, 16]这类配置按官方约束只能用cache_mode='default'。7 - 保留 baseline:原始
apply_rotary_pos_emb_absolute是数值基线,先用固定 seed 比对,再打开 fused。
MindSpeed-MM 的 verl 插件侧已经体现了这条路线:它会修改 vLLM Ascend 的 ops/rotary_embedding.py,把 torch_npu.npu_mrope(positions, ...) 中的 positions 改成 positions.contiguous(),说明真实 npu_mrope 落点在推理/rollout 的 q/k rotary apply,而不是 Megatron _preprocess 的 get_rotary_seq_len 分支。13
验证清单¶
| Case | 检查命令或断点 | 通过条件 |
|---|---|---|
| 分支 | 在 _preprocess 前打印 self.position_embedding_type。 |
Qwen3-VL 必须是 mrope。 |
| 对象 | 打印 type(self.rotary_pos_emb)。 |
Qwen3-VL 是 Qwen3VLMultimodalRotaryEmbedding。 |
| position ids | 打印 position_ids.shape。 |
BSHD 为 [3, B, S],THD 转换后仍保留三轴。 |
| fused 开关 | 打印 args.use_fused_rotary_pos_emb 和 config.apply_rope_fusion。 |
修分支时二者为 false;显式 npu_mrope 分支不依赖它们。 |
| npu_mrope 输入 | 打印 positions_2d/query_2d/key_2d/cos_sin_cache/head_size/mrope_section。 |
positions_2d 为 [3,T] 或 [4,T],query_2d/key_2d 为 [T,H*D],sum(mrope_section)=rotary_dim/2。 |
| interleave | 对比 cache_mode='interleave' 与原始 apply_interleaved_mrope 生成的 cos/sin。 |
H/W 通道分别写入 1::3、2::3 的位置。 |
| 数值 | 固定 seed,比对原始 Bridge MRoPE 与修改后输出。 | max_abs_diff 在 dtype 预期内;先测 BF16,再测 FP16。 |
| CP/packed | 覆盖 packed_seq_params is None 与 THD 两种路径。 |
is_thd_format、CP 切分和 cu_seqlens 不造成 shape 错位。 |
| profiler | 搜索 npu_mrope、npu_rotary_mul 或 MindSpeed rotary op。 |
普通 RoPE 看到 rotary fused op;Qwen3-VL fused 路径应看到 npu_mrope。 |
| 回退 | 关闭显式 npu_mrope 分支。 |
能稳定走 unfused MRoPE。 |
迁移边界¶
- 不要为 MRoPE 伪造
get_rotary_seq_len:即使补一个方法绕过 AttributeError,后续self.rotary_pos_emb(rotary_seq_len, packed_seq=...)仍和 Qwen3-VLforward(position_ids, mrope_section, ...)签名不匹配。 - 不要把
--position-embedding-type rope当作 fused MRoPE 开关:它只会改变 Megatron Core 的 Python 分支。 - 不要把
apply_rope_fusion=False理解成不能用 NPU rotary 算子:它只是在 Bridge/MCore 的普通 RoPE fusion 分支里必须关闭;独立torch_npu.npu_mrope分支可以另接。 - 不要把普通 TE / MindSpeed RoPE fusion 结论外推到 MRoPE:Megatron Core 0.16.1 在
apply_rope_fusion分支里已经提示:mRoPE 在 BSHD 且 batch size 大于 1 时会回退 unfused。19 - 不要先看 attention kernel:这个报错发生在进入 decoder 前的
_preprocess,还没到 q/k attention apply。 - 不要混淆两种 interleave:
rotary_mode='interleave'是 RoPE 旋转对布局;cache_mode='interleave'是 MRoPE 三轴 cos/sin cache 拼接布局。
参考文献¶
-
RoFormer: Enhanced Transformer with Rotary Position Embedding ↩
-
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution ↩
-
Ascend Extension for PyTorch 26.0.0:
torch_npu.npu_rotary_mul↩↩ -
Ascend Extension for PyTorch 26.0.0:
torch_npu.npu_interleave_rope↩↩ -
Ascend Extension for PyTorch 26.0.0:
torch_npu.npu_mrope↩↩↩↩ -
MindSpeed core_r0.16.0
arguments.py: fused rotary position embedding 参数校验 ↩ -
MindSpeed core_r0.16.0
fused_rope.py: NPU fused RoPE Python wrapper ↩ -
MindSpeed core_r0.16.0
npu_rotary_position_embedding.cpp: CANN op binding ↩↩ -
MindSpeed-MM master
modeling_qwen3_5_moe.py: FSDP Qwen3.5 MoE text/vision attention usestorch_npu.npu_rotary_mul↩↩↩ -
MindSpeed-MM master
glm4v_vl_vit_model.py:npu_rotary_mul(..., rotary_mode='interleave')↩ -
MindSpeed-MM master
verl_plugin/setup.py: patch vLLM Ascendtorch_npu.npu_mrope(positions.contiguous(), ...)↩ -
MindSpeed-MM master
modules.py: Qwen3.5apply_interleaved_mropewrites H/W freqs into stride-3 positions ↩↩↩ -
MindSpeed-MM master
modules.py:apply_rotary_pos_emb_absoluteassertsnot config.apply_rope_fusion↩↩ -
Megatron-LM core_v0.16.1
gpt_model.py:position_embedding_type初始化优先级 ↩ -
Megatron-LM core_v0.16.1
gpt_model.py: RoPE/MRoPE preprocess branches ↩ -
Megatron-LM core_v0.16.1
rotary_pos_embedding.py:get_rotary_seq_len↩ -
Megatron-LM core_v0.16.1
rope_utils.py: mRoPE fused fallback warning ↩ -
Megatron Bridge 0.4.0 API:
Qwen3VLMultimodalRotaryEmbedding↩↩ -
Megatron-Bridge v0.4.0
text_model.py:Qwen3VLGPTModelrebuilds rotary_pos_emb ↩ -
Megatron-Bridge v0.4.0
model.py: Qwen3-VL position_ids generation and language_model call ↩