BSND TND Operator Layout
导言
讨论 BSND/TND 时,最容易误判的是把 推理 prefill 支持 当成 训练全链路支持。对 Qwen3.5 这类含 Gated Delta Net 的模型,TND 不只是把 [B, S, N, D] reshape 成 [T, N, D]:训练还要覆盖 backward、recurrent state、cu_seqlens、label / loss mask、old logprob、ref logprob、actor update 和框架并行契约。
本文的结论是:推理 TND 是中等工程量,训练 TND 是大工程量;verl 已经支持 Qwen3.5 RL,但具体 layout 支持取决于 FSDP/Megatron/MindSpeed/vLLM 路径,不能一概而论。
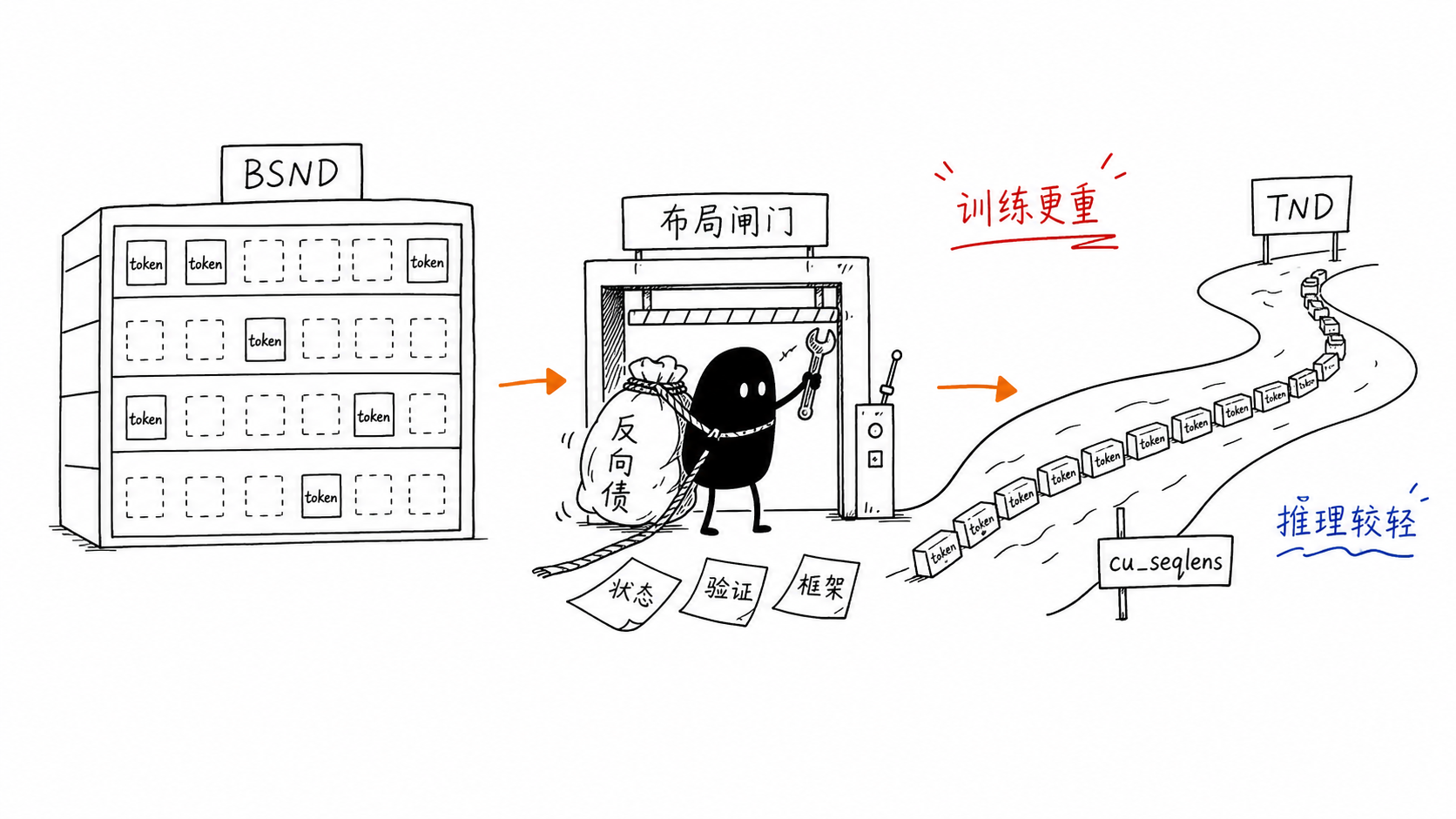
术语边界¶
本文把 BSND 写成 [B, S, N, D]:B 是 batch,S 是 sequence length,N 是 head 数,D 是 head dim。很多上游代码会把同一类 layout 写成 BSHD,其中 H 表示 heads;本文只在解释用户问题时用 N,引用上游时保留 H。
TND 写成 [T, N, D]:T 是一个 micro-batch 或 packed batch 内的 total tokens。它通常需要额外的边界元数据,例如 cu_seqlens、offsets、indices 或 segment ids。FlashAttention、FlashInfer、Megatron THD 语境里常写成 THD。
两者的关键差别不是张量阶数,而是 序列边界放在哪里:
- BSND/BSHD:边界藏在规则矩形里,padding 让 batch 对齐。
- TND/THD:边界外置为
cu_seqlens等元数据,token 连续排布。
这也是工作量差异的根源:TND 让有效 token 更紧凑,但把边界、状态、mask 和反向传播契约显式推给 operator 和 framework。
推理路径¶
推理侧最容易从 TND 受益的是 prefill。多个不同长度请求进入同一个 batch 时,TND 可以把有效 token 连成一条流,用 cu_seqlens 告诉 kernel 每个请求从哪里开始、在哪里结束。FlashInfer 的 GDN prefill API 就是这个形态:q/k/v 是 [total_seq_len, num_heads, head_size],cu_seqlens 是必填 varlen 元数据。1
对线性注意力或 GDN,decode 阶段还要维护状态。它不再像普通 attention 那样只读完整 KV cache,而是围绕 recurrent state 做读写。推理侧的主要难点通常是:
- prefill packing:把多请求 token 压成 TND,并保持
cu_seqlens正确。 - state 边界:每个请求的 GDN state 不能串到另一个请求。
- 后端覆盖:FlashInfer/FLA/vLLM 的具体 kernel 是否支持当前 head dim、dtype、SM/NPU 后端和并发模式。
所以推理 TND 可以说是 中等工程量:只要 serving 后端已经提供 varlen kernel,框架主要做路由、metadata 和状态管理;如果要自己写 kernel,就是更高一档。
训练路径¶
训练侧不能只看 forward。FLA 的 chunk_gated_delta_rule 主文档写的是 [B, T, H, K/V],同时支持 cu_seqlens;但它要求 varlen 输入先 flatten 成 B=1,并用 cu_seqlens 标出每条序列。2 这说明 FLA 不是完全无 batch 概念,而是用一个 rank-4 wrapper 承载 packed-token 语义。
更重要的是,训练要多处理反向图。以 FLA GDN 为例,forward 里有 chunk-local cumsum、WY 表示、state recurrence 和输出读出;backward 还要回传 dq/dk/dv/db/dg/dh0,并处理 reverse cumsum、initial/final state、chunk indices 和 context parallel context。2
因此训练 TND 的真实工作量包括:
- operator forward:TND/varlen 输入、chunk index、state 输入输出、dtype 和对齐。
- operator backward:所有梯度、state 梯度、gate 梯度和 recompute 路径。
- framework metadata:
cu_seqlens、offsets、position ids、labels、loss mask、attention mask、logits processor 输入必须同步。 - RL 子路径一致性:actor update、old logprob、ref logprob、rollout logprob、可选 distillation 都要吃同一种 layout。
- 并行边界:DP/TP/EP/CP/SP 下的 token 切分、state 切分和通信约定必须一致。
所以训练 TND 是 大工程量。它不是一个 reshape,也不是只把 FLA import 进来;它是 operator、模型 patch、训练引擎和 RL 数据流的共同契约。
Qwen3.5 案例¶
Qwen3.5 官方博客把 Qwen3.5-397B-A17B 描述为 Hybrid 架构:通过 Gated Delta Networks 引入 linear attention,并结合 sparse MoE。3 Qwen3.5-Omni 技术报告也把 GDN 放在长上下文、streaming 和 concurrency 的设计背景里。4
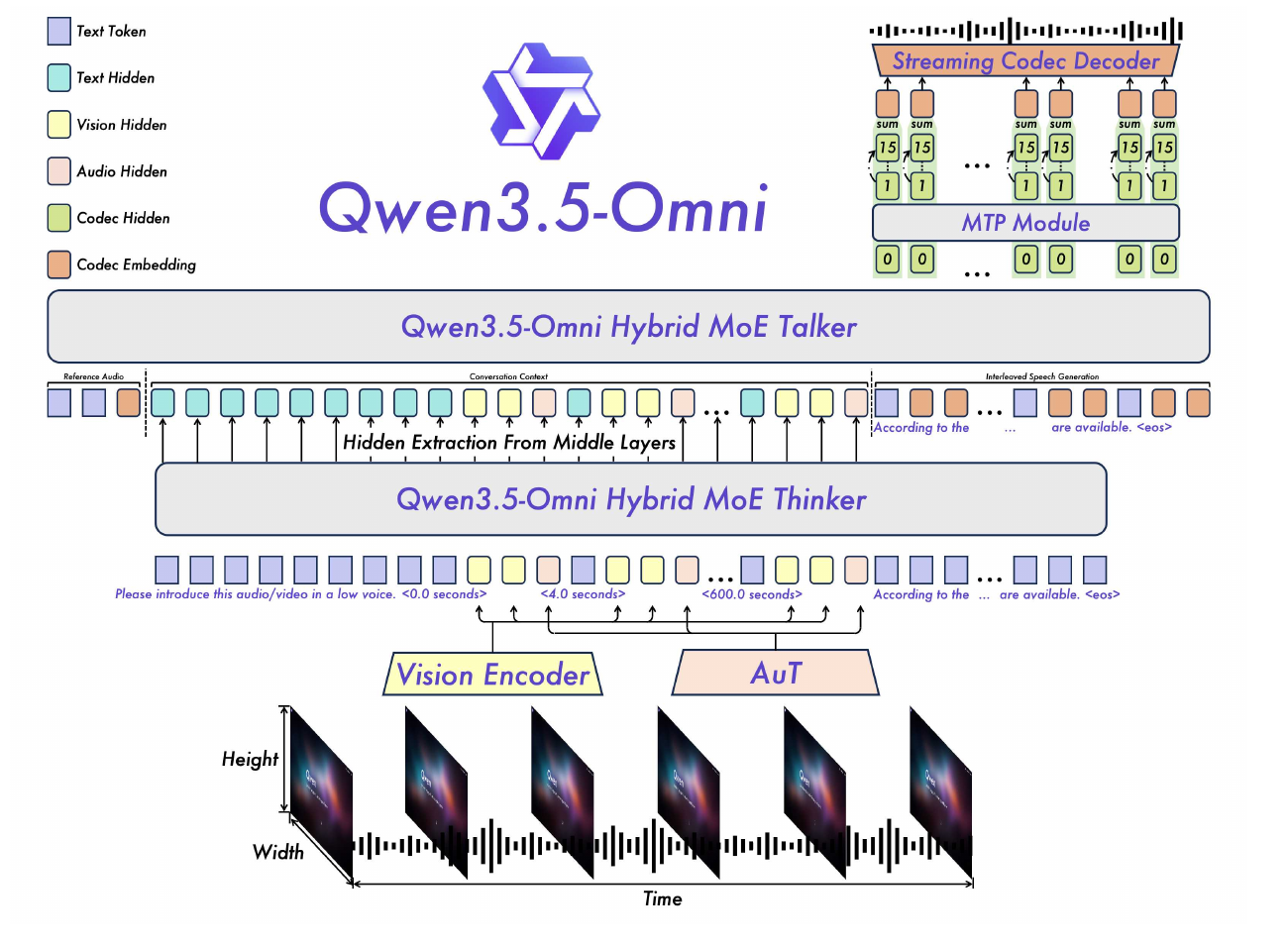
这和 BSND/TND 的关系是:GDN 的系统动机来自长序列效率和状态化建模,但状态化 operator 对训练 layout 更敏感。普通 RMSNorm、RoPE、GMM 这类算子迁移,很多时候只要处理 dtype、shape 和 forward/backward;GDN 还要处理 chunk recurrence、state 和 varlen 边界。
从 Qwen3.5 反推 flash-linear-attention 类工作量,可以分三档:
| 目标 | 工作量 | 关键原因 |
|---|---|---|
| 只在推理 prefill 走已有 TND kernel | M | 主要做 tensor packing、cu_seqlens、state 管理和后端路由。 |
| 在训练 forward 接入 FLA/FlashInfer 风格 varlen | L | 要接模型 forward、position/mask、state、dtype、fallback,并保证 actor/ref/logprob 路径一致。 |
| 在 NPU 上支持 Qwen3.5 GDN 训练 TND | XL | 还要补 forward/backward kernel、Ascend/Triton 版本矩阵、长序列、CP/SP、数值一致性和长跑稳定性。 |
一个容易犯错的说法是:“FLA 支持 cu_seqlens,所以训练支持 TND。”更准确的说法应该是:FLA 的某个 operator 接口支持 varlen 语义;目标训练框架是否能把 Qwen3.5 RL 全链路路由到这个接口,需要单独验证。
verl 支持什么¶
verl 的通用性能文档推荐两类优化:use_remove_padding=True 用于 sequence packing,use_dynamic_bsz=True 用于让每个 forward/backward 处理相近 token 数。文档还说 Qwen-family 模型可以启用 remove padding,但其他模型需要测试和注册。5
但 Qwen3.5 是一个反例式提醒:框架总体支持 packing,不等于某个模型后端已经支持 THD/TND。
公开脚本里至少有三种状态:
-
Qwen3.5 FSDP2 GRPO
run_qwen3_5_35b_fsdp.sh中actor_rollout_ref.model.use_remove_padding=True,actor 使用 FSDP2,rollout 使用 vLLM;但actor.use_dynamic_bsz=False。6 这说明 FSDP2 路径已经更接近 remove-padding/packed 训练路径,但不代表所有动态 batch 组合都打开。 -
Qwen3.5 Megatron GRPO
run_qwen3_5_35b_megatron.sh的注释明确写出:Qwen3.5 使用 GDN linear attention,而 Megatron-LM 当前不支持 packed sequences / THD format,所以脚本设置model.use_remove_padding=False、actor.megatron.use_remove_padding=False、actor.use_dynamic_bsz=False。7 verl 的 Qwen3.5 Megatron NPU 指南也重复了这个限制。8 -
NPU 支持矩阵
verl NPU support matrix 已列出 Qwen3.5-27B / 35B-A3B 的 GRPO FSDP2、MindSpeed-MM 路径,以及 Qwen3.5-122B-A10B 的 Megatron GRPO 路径。9 这说明 Qwen3.5 RL 是支持项,但 layout 仍由 engine 决定。
所以回答“verl 仓的 RL 支持哪种”要拆开:
| 问题 | 结论 |
|---|---|
| 算法支持 | NPU 表中 Qwen3/Qwen3.5 覆盖 GRPO、DAPO、PPO、SAPO、GSPO、fully_async 等多个入口;Qwen3.5 公开项以 GRPO 为主。 |
| FSDP2 Qwen3.5 | 支持 Qwen3.5 GRPO,示例开启 model.use_remove_padding=True,但动态 batch 没有全开。 |
| Megatron Qwen3.5 | 当前公开脚本保持 BSND/BSHD,不走 packed THD/TND,因为 GDN 的 Megatron THD 支持未完成。 |
| rollout 推理 | vLLM/FlashInfer 可以在 serving 内部使用自己的 packed token 管理,但这不自动证明训练 actor/ref/logprob 也支持 TND。 |
| fully async RL | fully async 解决 Trainer/Rollouter 解耦、staleness 和资源配比;它不替代底层 layout 支持。10 |
工作量判断¶
如果只问“BSND 和 TND 哪个更难”,答案太粗。更实用的分级是:
| 场景 | 原理 | 工作量 | 主要风险 |
|---|---|---|---|
| BSND 推理 | padded batch 直接进模型,batch 边界天然存在。 | S-M | padding 浪费、shape 变化导致编译/cache 抖动。 |
| BSND 训练 | labels/masks 容易对齐,actor/ref/logprob 边界清楚。 | M | padding 带来显存、attention mask 和低有效 token 密度。 |
| TND 推理 | token-major prefill 加 cu_seqlens,decode 维护 per-request state。 |
M | state 串扰、backend shape/dtype 覆盖不足。 |
| TND 训练 | token-major forward/backward 加外置边界元数据。 | L-XL | backward、state、CP/SP、loss mask、动态 batch 和长跑稳定性。 |
| Qwen3.5 GDN NPU 训练 TND | GDN chunk recurrence + varlen + RL 子路径。 | XL | 不能只移植 forward;必须补 backward 和全链路验证。 |
对 flash-linear-attention 这类库,最小可行路线建议分阶段:
- 先跑 BSND baseline:固定模型、数据、长度分布和并行配置,建立 loss/logprob/step time 基线。
- 只替换一个 operator forward:验证同输入下 eager vs fused 输出、final state 和 dtype。
- 补 backward parity:检查
dq/dk/dv/db/dg/dh0,尤其是 gate reverse cumsum 和 state 梯度。 - 再接 varlen/TND:引入
cu_seqlens、chunk indices、labels/loss masks,并覆盖空 batch、短长混合和最大长度。 - 最后进 RL 长跑:验证 actor update、old logprob、ref logprob、rollout weight sync、checkpoint 恢复和 NPU profiler。
验证清单¶
如果要在 verl 里推进 Qwen3.5 TND/THD 支持,我会要求至少补以下证据:
- 单算子数值:同一
q/k/v/g/beta/state下 eager、FLA/Triton、目标 NPU kernel 输出和梯度对齐。 - layout 等价:BSND padded 与 TND packed 在去 padding 后的有效 token 结果一致。
- RL 子路径:actor、ref、old logprob、rollout logprob、可选 distillation 都能跑同一 layout。
- 并行组合:覆盖 TP、EP、CP/SP、FSDP2/Megatron、MindSpeed-MM 分支。
- 边界样本:空 batch、极短序列、长短混合、超长序列、VLM 多模态位置编码。
- 性能归因:不要只报 total step;至少拆 old logprob、actor update、rollout、ref、HBM peak、host CPU 和 kernel time。
- 回退开关:保留一键回到 BSND/eager 的配置,避免长跑中无法定位问题。
结论¶
BSND/TND 的核心不是“哪个 layout 更高级”,而是 当前模型、operator、框架和训练工作流是否共享同一个边界契约。Qwen3.5 GDN 把这个问题放大了:推理可以先受益于 TND prefill 和 state 管理,但训练必须补齐 backward、state、metadata、并行和 RL 子路径。
对 verl 来说,正确结论是:Qwen3.5 RL 已经有公开支持路径;FSDP2 更接近 remove-padding/packed 训练,Megatron Qwen3.5 当前公开脚本仍是 BSND/BSHD。 如果要从 Qwen3.5 推进到 flash-linear-attention 或 NPU GDN TND 训练,应该按 L/XL 级工程来估,不要按一个接口参数来估。
参考文献¶
-
FlashInfer
gdn_prefill.py: https://github.com/flashinfer-ai/flashinfer/blob/main/flashinfer/gdn_prefill.py ↩ -
Flash Linear Attention
chunk_gated_delta_rule: https://github.com/fla-org/flash-linear-attention/blob/main/fla/ops/gated_delta_rule/chunk.py ↩↩ -
Qwen3.5 official blog: https://www.alibabacloud.com/blog/qwen3-5-towards-native-multimodal-agents_602894 ↩
-
Qwen3.5-Omni Technical Report, arXiv:2604.15804. https://arxiv.org/abs/2604.15804 ↩
-
verl Performance Tuning Guide: https://github.com/verl-project/verl/blob/main/docs/perf/perf_tuning.rst ↩
-
verl Qwen3.5-35B FSDP GRPO script: https://github.com/verl-project/verl/blob/main/examples/grpo_trainer/run_qwen3_5_35b_fsdp.sh ↩
-
verl Qwen3.5-35B Megatron GRPO script: https://github.com/verl-project/verl/blob/main/examples/grpo_trainer/run_qwen3_5_35b_megatron.sh ↩
-
verl Qwen3.5 Megatron NPU guide: https://github.com/verl-project/verl/blob/main/docs/ascend_tutorial/model_support/examples/qwen3_5_megatron_npu.md ↩
-
verl NPU Model & Algorithms Support Status: https://github.com/verl-project/verl/blob/main/docs/ascend_tutorial/model_support/model_and_algorithm_support.md ↩
-
verl Fully Async Policy Trainer: https://github.com/verl-project/verl/blob/main/docs/advance/fully_async.md ↩
-
Gated Delta Networks, arXiv:2412.06464. https://arxiv.org/abs/2412.06464 ↩