Scaling Law
导言
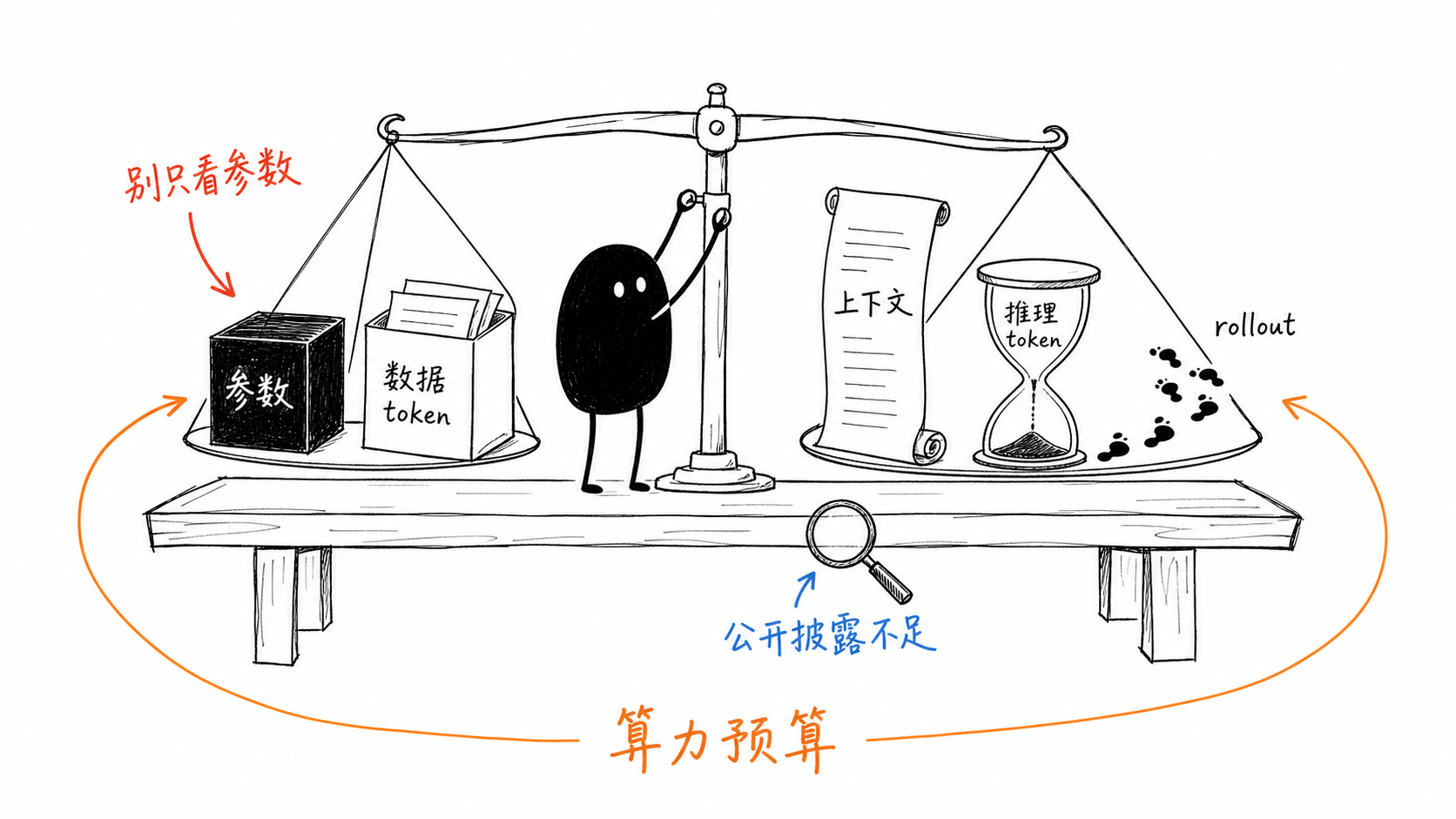
Scaling Law 不只是“模型越大越好”的经验总结,而是一套算力预算分配语言:在固定训练预算下,参数量、训练数据、序列长度和训练时长互相竞争;在固定推理预算下,模型大小、生成 token、采样策略、工具调用和 agent rollout 也互相竞争。本文只记录论文中可追溯的公开披露;没有披露的数据明确标为“未披露”,不从参数规模反推训练成本。
问题定义¶
讨论 Scaling Law 时,最容易混在一起的量至少有六类:
- 模型大小:Dense 模型通常看参数量
N;MoE 模型必须同时看 总参数量 和 每 token 激活参数量。总参数影响存储、通信和专家管理,激活参数更接近每 token 前向计算量。 - 训练数据量:语言模型常用 token 数
D;多模态模型还要看图片/视频 pair、帧数、分辨率、caption 质量和数据过滤强度。 - 序列长度:预训练阶段常从 4K 或 8K 开始,长上下文通常在 mid-training 或 context extension 阶段扩到 32K、64K、128K。
- 训练时长:可以写成 GPU/NPU hours,也可以写成在某个集群上的 wall-clock days。只有论文同时披露设备数和 GPU hours 时,才适合换算天数。
- 推理时长:不只是 prefill/decode 的延迟,还包括生成 token 数、采样次数、搜索策略、verifier 调用和缓存策略。
- Agent 预算:agent 的 test-time compute 还包含工具调用、环境交互、反思、并行 rollout、候选答案选择和 reward/verifier 计算。
不要只看参数
参数量只是规模的一种投影。DeepSeek-V3 是 671B 总参数、37B 激活参数;Qwen3-235B-A22B 是 235B 总参数、22B 激活参数;LongCat-Flash 是 560B 总参数、平均约 27B 激活参数。把 MoE 总参数直接当作每 token 计算量,会系统性误读训练和推理成本。
训练侧的 Law¶
早期语言模型 Scaling Law 的主问题是:给定训练 compute,应该把预算投给更大的模型,还是更多的数据?
Kaplan 等人的结论是,语言模型 loss 会随模型大小、数据集大小和训练 compute 呈近似 power-law 改善。后续 Chinchilla 论文指出,如果使用近似训练 FLOPs:
那么在 compute 增大时,参数量 N 和训练 token 数 D 应接近等比例增长。Chinchilla 的 70B 模型使用约 1.4T tokens,论文认为当时许多大模型是 under-trained:参数做大了,但训练 token 没有同步增加。
这个结论的实践含义很直接:
- 模型变大不是免费收益:参数增长会消耗训练 compute,也会抬高推理成本。
- 数据变多也不是免费收益:低质量重复数据会污染 loss 曲线,长尾高质量数据更稀缺。
- 长上下文通常不是预训练第一阶段完成:许多公开模型先用短序列学通用能力,再用 32K/128K 数据做 context extension。
推理侧的 Law¶
2024 年之后,Scaling Law 的讨论从训练预算延伸到推理预算。推理时也有一个 compute-optimal 问题:给定推理 FLOPs,是使用更大的模型一次回答,还是使用较小模型多次采样、搜索、验证和反思?
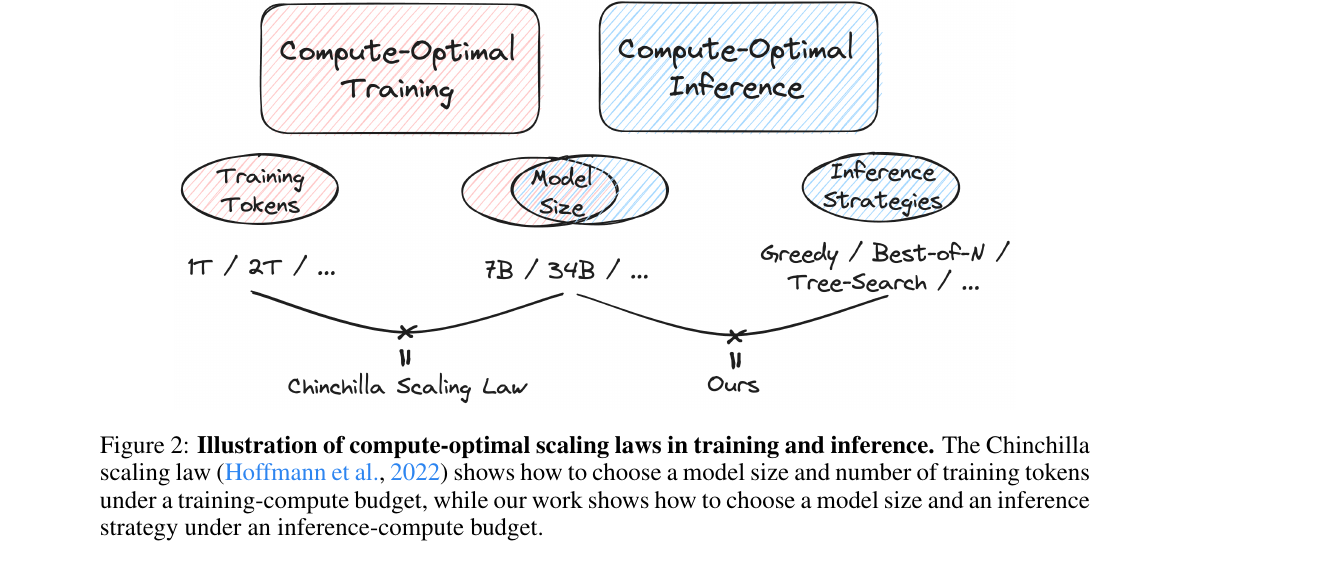
Inference Scaling 论文把推理侧变量写成模型大小 N、生成 token 数 T 和策略 S。这使 Scaling Law 从“训练一个模型”变成“训练与推理共同组成的系统优化”。
Agent 场景进一步放大了这个问题。Test-time compute 可以花在:
- Parallel sampling / Best-of-N:同一问题生成多个候选,再用 verifier 或 reward 选择。
- Reflection / self-refinement:让模型检查、修正和重写自己的轨迹。
- Diversified rollout:让候选轨迹在工具、计划或解题路径上有差异,而不是重复采样近似答案。
- List-wise verification:一次比较多个候选,而不是逐个打分。
- Tool and environment calls:真实 agent 的成本还包含外部工具延迟、API 费用和环境状态转移。
Agent Scaling Law
在 agent 系统里,推理时长不再只是 decode latency。一个回答可能包含规划、搜索、工具调用、环境执行、反思、验证和重试。Scaling Law 因此从模型内部的 N, D, C 扩展到系统层的 rollout budget。
规模如何逐年增加¶
下面的表只放论文可追溯披露。GPT-3 和 Chinchilla 不是开源模型,但它们是理解后续开源模型规模增长的历史基准。
| 年份 | 模型/论文 | 形态 | 参数规模 | 训练数据或规模 | 上下文/序列长度 | 训练机器与时长 |
|---|---|---|---|---|---|---|
| 2020 | GPT-3 | Dense LLM | 175B | 约 300B tokens | 2K | 未披露完整训练 wall-clock |
| 2022 | Chinchilla | Dense LLM | 70B | 1.4T tokens | 2K 级别实验设置 | 与 Gopher 同量级 compute,具体集群天数未披露 |
| 2024 | DeepSeek-V3 | MoE LLM | 671B total / 37B active | 14.8T tokens | 4K pre-train,扩到 32K/128K | 2048 H800;总 2.788M H800 GPU hours,约 56.7 个集群日 |
| 2025 | DeepSeek-R1 | Reasoning LLM | 基于 DeepSeek-V3-Base | 804,745 条 SFT reasoning data,平均 5,355 tokens | SFT/RL max 32K,R1-Zero 后期 65,536 | R1-Zero 约 101K H800 GPU hours,R1 约 41K H800 GPU hours |
| 2025 | Qwen3 | Dense + MoE LLM | 最大 235B total / 22B active | 36T tokens | 4K 阶段训练,32K 长上下文训练,128K 推理上下文 | 未披露完整集群天数;Qwen3-8B 直接 RL 17,920 GPU hours,对比 on-policy distillation 1,800 GPU hours |
| 2025 | GLM-4.5 | MoE LLM | 355B total / 32B active | 23T tokens | 4K -> 32K -> 128K | 未披露完整 GPU days |
| 2025 | Wan | Video diffusion | 1.3B / 14B | billions of videos and images;post-training 使用 millions 级 curated images/videos | 视频时长、分辨率和 latent 序列共同决定 | 未披露完整 GPU days |
| 2025 | LongCat-Flash | MoE LLM | 560B total / avg 27B active | 超过 20T tokens | 8K -> 32K -> 128K | 论文称 30 天内完成 >20T 预训练;具体设备数未完整披露 |
| 2025 | Pangu Pro MoE | MoE LLM | 约 72B total / 16B active | 13T tokens | 4K -> 32K | 4K 张 Ascend NPU;wall-clock days 未披露 |
| 2025 | Qwen-Image | Text-to-image | 20B MMDiT + 7B Qwen2.5-VL encoder | billions of image-text pairs | 最高到 1328p 图像分辨率 | 未披露完整 GPU days |
| 2026 | Qwen-Image-2.0 / RL | Omni image model | 条件编码器基于 Qwen3-VL;核心生成模型规模未在摘要级披露 | pretraining 700K steps,continual pretraining 250K steps;后续 SFT/RLHF/OPD | prompt up to 1K tokens,native 2K resolution | 未披露完整 GPU days |
这张表背后的趋势不是“每年参数都单调变大”,而是规模的定义变多了:
- 语言模型从 dense 参数扩展到 MoE 的 total/active 双尺度。
- 数据规模从百亿、千亿 tokens 进入十万亿、数十万亿 tokens。
- 上下文长度从 2K/4K 变成 32K/128K 的训练和推理能力。
- 多模态模型把“数据量”改写成图片/视频数量、分辨率、帧数、caption 质量和任务混合。
- 后训练从小规模 SFT 变成冷启动、拒绝采样、RL、distillation、verifier 和 agent 任务的组合工程。
后训练披露矩阵¶
SFT 和 RL 是最容易被营销材料简化的部分。很多论文会披露“使用 SFT + RL”,但不披露样本数、平均长度、GPU hours 或设备数。下表把已披露与未披露分开。
| 模型 | SFT 数据量 | RL 数据量/步骤 | 长度设置 | 机器与时长 | 未披露项 |
|---|---|---|---|---|---|
| DeepSeek-V3 | 使用专家模型和 R1 生成数据,SFT 2 epochs;精确样本数未披露 | 使用 GRPO;精确样本数未披露 | pre-training 4K;context extension 32K 与 128K 各 1000 steps | post-training 5K H800 GPU hours;全训练 2.788M H800 GPU hours | SFT/RL 样本数、平均长度、单独 RL GPU days |
| DeepSeek-R1 | 804,745 条 supervised data;平均 5,355 tokens;SFT 2-3 epochs | R1-Zero 10,400 steps;每问题 16 outputs;第二阶段 RL 1,700 steps | SFT max 32K;R1-Zero 早期 32,768,后期 65,536 | 64x8 H800;R1-Zero 约 198 小时;R1 约 80 小时;总 147K H800 GPU hours | 冷启动“数千条”数据的精确构成 |
| Qwen3 | Thinking/non-thinking fusion SFT;精确总样本数未披露 | reasoning RL 使用 3,995 query-verifier pairs;Qwen3-235B-A22B 约 170 RL steps | 4K 主训练;长上下文阶段 32K,推理 128K | Qwen3-8B 直接 RL 17,920 GPU hours;on-policy distillation 1,800 GPU hours | 最大模型完整 post-training GPU days |
| GLM-4.5 | 两阶段 expert/unified training 都包含 SFT;overall SFT millions of samples | reasoning RL 使用 GRPO;agent/general chat 也进入统一训练 | SFT max context 128K;pretrain/midtrain 4K -> 32K -> 128K | 未披露完整 GPU days | 各阶段样本数、RL steps、设备数 |
| LongCat-Flash-Thinking | reasoning-oriented SFT,2 epochs | large-scale RL + general RL;DORA 异步 RL,比同步快 3x 以上 | SFT 48K;STEM RL 64K;Code RL 48K->56K->64K;Agentic 48K | 论文称 RL 在 tens of thousands accelerators 上稳定运行,RL compute 接近 pretraining compute 的 20% | 样本数、GPU hours、精确设备数 |
| Pangu Pro MoE | SFT reasoning:non-reasoning = 3:1;六轮 progressive optimization | GRPO + Zero-Advantage-Mask | general 4K;reasoning/annealing 32K | 4K 张 Ascend NPU 训练预训练;post-training days 未披露 | SFT 样本数、RL steps、post-training GPU/NPU hours |
| Pangu Embedded | model-aware iterative distillation;数据池来自开源指令、工业查询、合成语料 | math RL 验证约 30,000 ORZ Math;code RL 验证 16,384 prompts,code RL 300 steps | 论文主要披露验证集与训练框架,长度不完整 | Ascend 集群 + MARS;完整天数未披露 | 完整 SFT/RL 数据规模与硬件天数 |
| Wan | post-training 使用 millions 级 top-quality images、simple-motion videos、complex-motion videos | 论文主要披露视频生成 post-training 数据构成,不以 LLM RL 表述为主 | 由视频帧数、时长和 latent token 决定 | 未披露完整 GPU days | 每阶段 step、GPU hours、精确样本数 |
| Qwen-Image / 2.0 | Qwen-Image 使用 SFT;Qwen-Image-2.0 有 prompt enhancement SFT | DPO、GRPO、RLHF、OPD;2.0-RL 使用 task-specialized policies | 最高 1328p/2K resolution;prompt up to 1K tokens | 2.0 披露 pretraining 700K steps、continual pretraining 250K steps;GPU days 未披露 | 数据精确数量、RL steps、完整设备数 |

GPU hours 如何换成天数
如果论文披露 GPU hours 和设备数,可以用 GPU hours / GPU count / 24 估算 wall-clock days。例如 DeepSeek-V3 总 2.788M H800 GPU hours,若按 2048 H800 计算,约为 56.7 个集群日。没有设备数时,不应强行把 GPU hours 改写成训练天数。
多模态的尺度¶
多模态模型的 Scaling Law 更难直接对齐 LLM,因为 token 数只是其中一个维度。
以 Qwen-Image 和 Wan 为例,真正影响规模的变量包括:
- 样本形态:image-text pair、video-text pair、OCR 文本图像、合成 caption、偏好 pair。
- 视觉分辨率:256p、512p、1024p、1328p、2K 会显著改变 latent token 数和 attention/DiT 计算。
- 视频时间维:视频时长、帧率、运动复杂度会改变训练样本的信息量。
- 数据过滤:Wan 报告强调去除低质量、低运动和 synthetic contamination;Qwen-Image 报告按 Nature、Design、People、Synthetic 等域组织数据。
- 后训练目标:文本渲染、图像编辑、风格一致性、偏好对齐和 prompt enhancement 不是同一个训练目标。
因此,多模态论文里看到 “billions of image-text pairs” 或 “millions of curated videos” 时,不能把它简单等价成 LLM 的 token 数。更稳妥的做法是同时记录样本数量、分辨率、时长、任务类型和训练 step。
Agent 场景的尺度¶
Agent 的 Scaling Law 不是只问“模型多大”,而是问“在一个任务上愿意花多少次尝试”。一个 agent 任务的总预算可以粗略写成:
total_cost ~= model_cost_per_token
* generated_tokens_per_rollout
* rollout_count
+ verifier_cost
+ tool_cost
+ environment_latency
这解释了为什么较小模型在某些任务上可以通过更多 rollout 追上大模型,也解释了为什么真实 agent 评测必须报告:
- 每题采样次数:Best-of-N 的 N 直接改变 test-time compute。
- 最大输出长度:长 CoT、代码生成和工具轨迹会拉高 decode tokens。
- verifier/reward 成本:如果 verifier 本身很大,总成本不能只算 policy model。
- 工具调用次数:搜索、代码执行、浏览器操作和数据库查询都属于系统成本。
- 失败重试策略:反思和重试能提高成功率,但也可能让延迟和成本失控。
评测口径
只报告 benchmark 分数而不报告 test-time budget,会让 agent 模型比较失真。未来读 agent 论文时,应把 rollout 数、工具调用、verifier、最大 token 长度和 wall-clock latency 当作核心实验条件。
可复用记录规则¶
这次调研沉淀为 wiki 规则:obsidian-vault/wiki/meta/Scaling Law Evidence Rule.md。后续更新模型规模文章时,优先维护同一张证据矩阵:
- 模型名称、发布日期、论文链接。
- Dense/MoE,总参数与激活参数分开。
- pre-training、mid-training、context extension、SFT、RL、distillation 分阶段记录。
- 每阶段记录数据量、平均长度、最大上下文、设备数、GPU/NPU hours、wall-clock days。
- 对未披露项写“未披露”,不从 marketing claim 反推。
- 对多模态模型额外记录分辨率、帧数、时长、caption/OCR、偏好数据和 diffusion step。
小结¶
Scaling Law 的现代含义可以压缩成三句话:
- 训练侧:参数、数据和 compute 要配平;Chinchilla 之后,“更多 token”成为和“更多参数”同等重要的尺度。
- 推理侧:模型大小、生成长度、采样策略和 verifier 共同决定 test-time compute;agent 任务尤其需要报告 rollout budget。
- 披露侧:开源模型论文越来越愿意披露参数、tokens、context 和部分 GPU hours,但 SFT/RL 数据量、平均长度和完整设备天数仍经常缺失。
真正有用的 Scaling Law 阅读方式,不是把每个模型排成参数榜,而是把它们还原成一张预算表:钱花在参数、数据、上下文、推理、RL 和 agent rollout 的哪里。
参考文献¶
- Jared Kaplan et al., Scaling Laws for Neural Language Models.
- Jordan Hoffmann et al., Training Compute-Optimal Large Language Models.
- Tom B. Brown et al., Language Models are Few-Shot Learners.
- Charlie Snell et al., Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters.
- OPPO AI Agent Team, Scaling Test-time Compute for LLM Agents.
- DeepSeek-AI, DeepSeek-V3 Technical Report.
- DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.
- Qwen Team, Qwen3 Technical Report.
- Zhipu AI, GLM-4.5: Agentic, Reasoning, and Coding.
- Qwen Team, Qwen-Image Technical Report.
- Qwen Team, Qwen-Image-2.0 Technical Report.
- Qwen Team, Qwen-Image-2.0-RL Technical Report.
- Wan Team, Wan: Open and Advanced Large-Scale Video Generative Models.
- LongCat Team, LongCat-Flash Technical Report.
- LongCat Team, LongCat-Flash-Thinking Technical Report.
- Pangu Team, Pangu Embedded Technical Report.
- Pangu Team, Pangu Pro MoE Technical Report.