Training Performance Model
导言
模型训练建模不是先问“MFU 有多高”,而是先把模型结构、硬件账本、并行切分、调度路径和实测校准放到同一个估算器里。MFU 是其中最干净的计算口径:它把模型理论必需 FLOPs、设备峰值和实测步时连在一起;但显存能不能放下、通信会不会卡住、padding 是否浪费、EP/TP/SP 是否合适,必须另算。
建模闭环¶
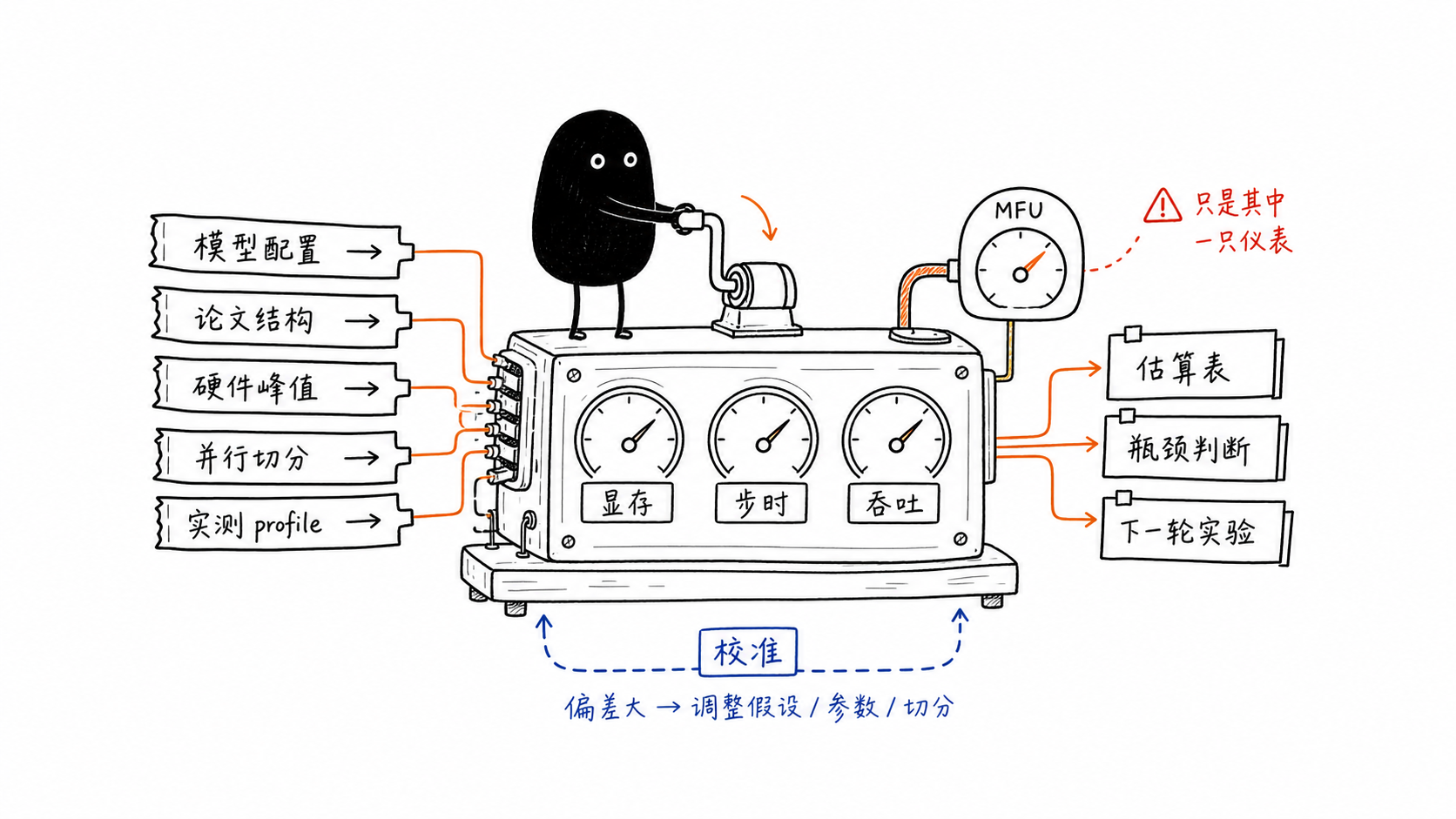
我希望这个系列解决两个连续问题:
- MFU 怎么算:以 PaLM 的定义为基准,再看 verl 代码里怎样把
batch_seqlens、delta_time、设备峰值和 world size 组合成perf/mfu/actor。 - 训练/推理怎么建模:输入 Hugging Face 配置、模型论文、特殊结构、硬件指标和集群规模,针对 EP、TP、SP/CP、序列长度和 batch size,输出显存估计、单步耗时、单卡吞吐,并能画出瓶颈变化。
一个可用的估算器至少要维护五本账:
- 计算账:dense/MoE/attention/GDN/loss/recompute/optimizer 分别消耗多少模型必需 FLOPs。
- 显存账:参数、梯度、优化器状态、activation、KV cache、expert buffer、通信 buffer 和碎片。
- 通信账:DP、TP、PP、SP/CP、EP all-to-all、权重同步和 offload 传输分别占多少。
- 调度账:global batch、micro batch、序列长度分布、PPO epochs、rollout
n、pipeline bubble 和 queue idle。 - 校准账:实测 step time、phase timing、内存水位、tokens/s、profile counter 和误差回填。
先分账再比较
不要直接比较两个实验的 MFU,除非模型结构、有效 token 口径、padding 策略、并行规模、设备峰值和计时区间都已经对齐。MFU 是计算效率指标,不是完整系统效率指标。
MFU 口径¶
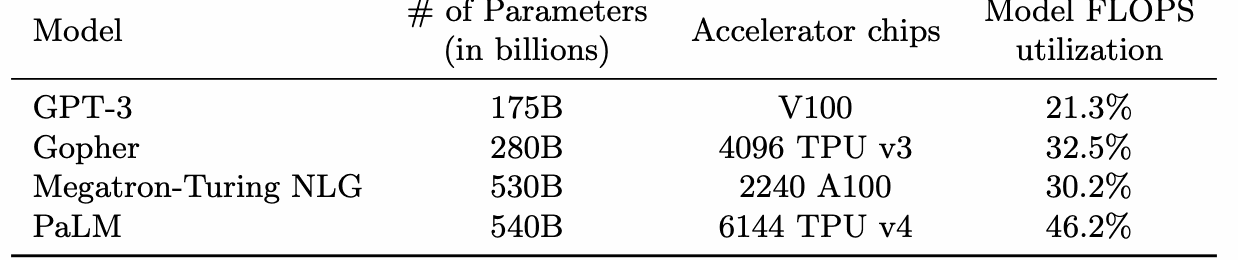
PaLM 论文把 MFU 定义为观测 token 吞吐相对理论最大 token 吞吐的比例。它刻意排除了 rematerialization 这类实现相关的额外硬件 FLOPs,只统计模型 forward+backward 必需操作,因此比 HFU 更适合跨系统比较。1
对 dense decoder-only Transformer,PaLM Appendix B 使用的粗略口径是:
required FLOPs/token ~= 6N + attention_term
MFU = observed_tokens_per_second * required_FLOPs_per_token / peak_FLOPs_per_second
其中 N 是参数量;6N 来自一次 forward 约 2N matmul FLOPs、一次 backward 约 4N matmul FLOPs。注意力项在大模型里通常比 MLP/linear 小,但长序列、GQA/MQA、滑窗/全注意力比例都会改变它。
这个定义给训练建模一个好处:分子是实测吞吐,分母只依赖模型结构和硬件峰值。但它也带来一个限制:如果实际 kernel 因 padding、recompute、offload、通信等待而多做或少做工作,MFU 本身不会解释原因。
verl 代码路径¶
截至 verl fa856c3d97fbf93c059322298cc24bec3a944bfe,MFU 的主路径在两个文件里:verl/utils/flops_counter.py 和 verl/workers/engine_workers.py。23
关键流程可以压成下面这段:
tokens_sum = sum(batch_seqlens)
estimated_flops = estimate_by_model_type(config, tokens_sum, batch_seqlens, delta_time)
promised_flops = get_device_flops()
mfu = estimated_flops / promised_flops / torch.distributed.get_world_size()
if forward_only:
mfu /= 3.0
代码里有三个细节特别重要:
- 设备峰值来自字符串匹配:
get_device_flops()将H100/H800/H200记为989e12,H20记为148e12,910B/A2G3/Ascend910记为354e12,最后按T单位返回。设备名无法匹配时会返回inf,MFU 会失真。 - 训练估算器默认是 forward+backward:
_estimate_qwen2_flops()和_estimate_qwen2_moe_flops()都用6 * N * tokens_sum。在infer_batch()或 old logprob 这类 forward-only 路径里,engine_workers.py会再除以3.0。 - 指标最后被 trainer 重命名:PPO V0/V1 里 actor 输出从
actor/mfu改成perf/mfu/actor,critic 改成perf/mfu/critic;old logprob 路径会记录perf/mfu/actor_infer。
verl 的 Qwen2/Qwen3 dense 公式近似为:
mlp_N = hidden_size * intermediate_size * 3
attn_linear_N = hidden_size * (q_size + k_size + v_size + o_size)
embedding_N = vocab_size * hidden_size * 2
dense_N = (mlp_N + attn_linear_N) * layers + embedding_N
flops = 6 * dense_N * valid_tokens
+ 6 * sum(seq_len_i^2) * head_dim * num_heads * layers
Qwen3 MoE 公式把 MLP 部分换成 active expert:
这里 hidden_size * num_experts 是 router gate 的线性层,top_k 只计算每个 token 实际激活的 expert MLP。这个口径适合“模型必需 FLOPs”,但它不等于 MoE 总参数显存,也不等于 EP all-to-all 的通信成本。
Qwen3.5 特例¶
Qwen3.5-35B-A3B 的模型卡写明:35B total、3B activated、40 层、hidden size 2048、256 experts、每 token 8 routed experts 加 1 shared expert,原生上下文 262,144;其 hidden layout 是 10 x (3 x (Gated DeltaNet -> MoE) -> 1 x (Gated Attention -> MoE))。4
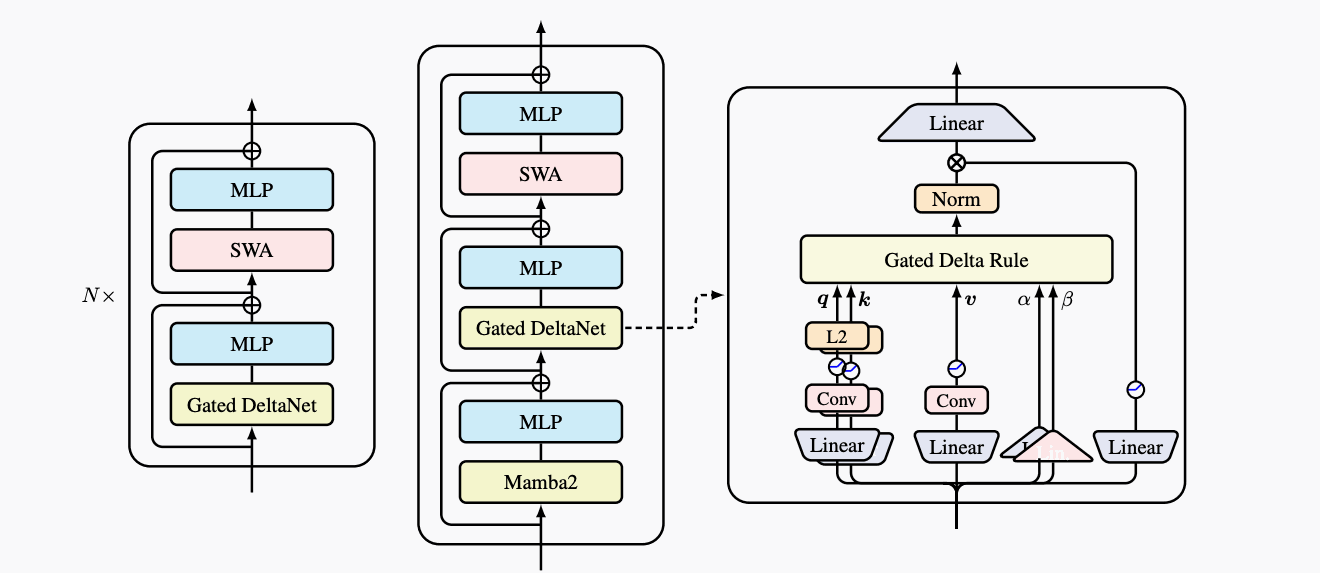
HF config.json 进一步给出两个容易踩坑的字段:顶层 model_type 是 qwen3_5_moe,文本子配置是 qwen3_5_moe_text;layer_types 里 30 层是 linear_attention,10 层是 full_attention。5
因此,Qwen3.5 的 MFU 需要把四件事分开:
- 当前 public verl 是否命中 estimator:观察到的
ESTIMATE_FUNC只注册了qwen3、qwen3_moe、qwen3_vl等类型,没有qwen3_5_moe。如果没有本地 patch,FlopsCounter会走_estimate_unknown_flops(),MFU 结果为 0。 - MoE active FLOPs 是否包含 shared expert:Qwen3.5 模型卡写的是
8 Routed + 1 Shared,而 publicqwen3_moe公式只按num_experts_per_tok计算 routed experts,并不自动加入 shared expert MLP。 - GDN 层不能按全注意力二次项收费:30 层
linear_attention的主序列项更接近线性递推/状态更新;直接套 Qwen3 MoE 的sum(seq_len_i^2) * layers会把这些层当成 full attention,方向上会高估 attention 二次项,同时漏掉 GDN 的 conv、L2 norm、gate、state update 和专用 kernel 成本。 - Megatron 示例关闭 packed token 路径:verl 的 Qwen3.5 Megatron GRPO 脚本明说 GDN 在 Megatron-LM 中还不支持 packed THD format,所以
model.use_remove_padding=False、actor.megatron.use_remove_padding=False、actor.use_dynamic_bsz=False。6
Qwen3.5 MFU 的第一版补丁
不要只把 qwen3_5_moe 映射到 qwen3_moe 就结束。更稳的做法是新增 estimate_qwen3_5_moe_flops(config, ...):先取 config.text_config,按 layer_types 区分 GDN 和 full attention,再把 routed expert、shared expert、router、GDN token mixer、MTP 和实际 loss 路径逐项列出。暂时无法确认的项应写成 unknown 或 calibrated_factor。
显存估计¶
训练显存不能从 active parameters 推出。MoE 的计算账看 active experts,显存账看驻留和分片后的总参数、梯度和优化器状态。
一个单卡显存下界可以写成:
M_card =
M_param_shard
+ M_grad_shard
+ M_optimizer_shard
+ M_activation_peak
+ M_kv_or_rollout_cache
+ M_comm_buffer
+ M_runtime_fragmentation
对 Qwen3.5-35B-A3B 这类 MoE/GDN 混合模型,至少要把下面字段显式化:
- 参数与优化器:total params、expert params、shared expert、embedding/lm head、optimizer dtype、ZeRO/FSDP/Megatron/EP shard 方式。
- activation:micro batch、sequence length、是否 full recompute、selective recompute、GDN state、MoE permute/unpermute buffer。
- KV 或 rollout cache:训练 actor update 通常不等于 vLLM rollout cache;推理吞吐建模必须单独算
max_model_len、KV dtype、TP shard 和并发请求。 - 通信 buffer:TP all-reduce/all-gather、EP all-to-all、PP send/recv、参数 offload staging buffer 都可能成为峰值的一部分。
- padding 影响:如果 Megatron 路径关闭 remove padding,显存和 kernel 工作量接近 padded shape,而不是只随 valid token 变化。
Megatron-Core 配置里已经把 recompute、activation offload、MoE recompute、shared_experts 和 gdn_norm_out 等选项作为显式字段,这说明显存模型需要和框架配置绑定,而不是只看模型参数。7
单步耗时¶
单步耗时建议拆成下界和校准两层:
T_step =
T_actor_train
+ T_old_logprob
+ T_ref_logprob
+ T_rollout
+ T_reward
+ T_critic_train
+ T_sync
+ T_runtime
对每个阶段先算三个物理下界:
T_compute >= FLOPs_phase / (num_devices * peak_FLOPs * compute_eff)
T_memory >= bytes_hbm_phase / (num_devices * hbm_bandwidth * mem_eff)
T_comm >= collective_bytes / (link_bandwidth * comm_eff) + latency_terms
再叠加调度项:
- PP bubble:Megatron-LM 论文指出 pipeline flush 会产生 bubble,microbatch 数相对 pipeline stage 越少,空泡比例越高。8
- TP/EP 通信:TP 通信多发生在层内;EP all-to-all 与 token 分布、top-k、expert load balance 相关。
- SP/CP:SP 能降 activation 内存,但会引入序列维度通信;CP 对长序列 attention/GDN 状态切分更敏感。
- RL rollout:GRPO/PPO 的 step 不只是 actor update;rollout
n、response length 长尾、reward 模型和 logprob 重算会改变端到端吞吐。
verl 的 Qwen3.5 Megatron GRPO 示例给了一个可以落表的起点:GPU 默认 TP=2, PP=1, CP=1, EP=8, ETP=1, GEN_TP=8, n_devices_per_node=8;NPU 默认 TP=2, PP=2, CP=1, EP=8, ETP=1, GEN_TP=8, n_devices_per_node=16。数据侧是 train_batch_size=32、max_prompt_length=1024、max_response_length=2048,rollout n=5,actor micro batch per GPU 是 1。6
这类配置可以生成第一版估算矩阵:
| 变量 | 影响方向 | 先看指标 |
|---|---|---|
EP 增大 |
单卡 expert 参数下降,EP all-to-all 上升 | expert load balance、all-to-all time、token drop/padding |
TP 增大 |
单卡 GEMM 变小,TP 通信上升 | matmul efficiency、all-reduce time、kernel occupancy |
PP 增大 |
单卡层数下降,bubble 上升 | microbatch 数、PP send/recv、空泡比例 |
SP/CP 打开 |
activation 下降,序列通信上升 | activation peak、sequence collective、长序列效率 |
| 序列长度增加 | attention/GDN/KV/activation 增加 | full attention 层、GDN state、KV cache |
| micro batch 变化 | kernel 效率和 activation 峰值同时变 | step time、OOM margin、tokens/s/card |
吞吐可视化¶
可视化不应该只画一个 MFU 曲线。第一版 dashboard 至少需要四组图:
- 显存堆叠条形图:参数、梯度、优化器、activation、KV、buffer、碎片。
- 单步耗时瀑布图:compute、HBM、TP、EP、PP bubble、offload、runtime overhead。
- 单卡吞吐热力图:横轴 sequence length,纵轴 global batch 或 micro batch,颜色为 tokens/s/card。
- 并行配置对比图:不同
EP/TP/PP/SP下的 MFU、显存余量、通信占比和 step time。
输出数据可以先用一张长表承载:
model, commit, device, n_cards, ep, tp, pp, sp, cp,
seq_prompt, seq_response, global_batch, micro_batch,
param_gb, optim_gb, activation_gb, kv_gb, buffer_gb,
flops_required, t_compute, t_memory, t_comm, t_step,
tokens_per_s, tokens_per_s_per_card, mfu, calibration_note
什么时候相信估算
估算器不是为了替代 profile,而是为了决定下一轮实验。只要它能稳定解释“为什么这个配置会 OOM / 为什么这个 TP 更慢 / 为什么 MFU 上升但端到端吞吐没升”,就已经有工程价值。
下一步¶
这个系列后续可以拆成三篇:
- MFU Calculator:把 PaLM、Megatron、verl 的 FLOPs 口径统一成可执行脚本,并补 Qwen3.5/GDN/MoE 的 estimator。
- Memory Model:按 FSDP/Megatron/EP/TP/SP/PP 估参数、optimizer、activation、KV 和通信 buffer。
- Throughput Visualizer:把典型配置扫成热力图,结合实测 profile 自动回填
compute_eff、comm_eff和 padding penalty。
长期看,最重要的不是某个公式,而是把每次调参都沉淀成可追溯账本:来源来自论文、配置和源码;假设写在估算器里;偏差由 profile 校准;下一轮实验只改一个主变量。
可复用提示词¶
请基于一手资料为下面模型/训练配置建立性能模型:
1. 读取 HF config、模型卡、论文、训练脚本和框架源码。
2. 区分 total parameters、active parameters、MoE routed/shared experts、attention 类型、linear attention 或特殊算子。
3. 给出显存估计、单步耗时估计、单卡吞吐、MFU 计算口径和当前公式的已知偏差。
4. 对 EP、TP、PP、SP/CP、序列长度、global batch、micro batch 做敏感性分析。
5. 把源码事实、公式假设、实测校准和仍未知字段分开写。
6. 输出可视化所需的表格字段和图表建议。
该提示词已经沉淀为 wiki 规则:obsidian-vault/wiki/meta/Training Performance Modeling Rule.md。
参考文献¶
-
Chowdhery et al., PaLM: Scaling Language Modeling with Pathways, Appendix B and Section 4.1. https://arxiv.org/abs/2204.02311 ↩
-
verl
flops_counter.py, commitfa856c3d97fbf93c059322298cc24bec3a944bfe. https://github.com/verl-project/verl/blob/fa856c3d97fbf93c059322298cc24bec3a944bfe/verl/utils/flops_counter.py ↩ -
verl
engine_workers.py, commitfa856c3d97fbf93c059322298cc24bec3a944bfe. https://github.com/verl-project/verl/blob/fa856c3d97fbf93c059322298cc24bec3a944bfe/verl/workers/engine_workers.py ↩ -
Qwen3.5-35B-A3B model card. https://huggingface.co/Qwen/Qwen3.5-35B-A3B ↩
-
Qwen3.5-35B-A3B
config.json. https://huggingface.co/Qwen/Qwen3.5-35B-A3B/blob/main/config.json ↩ -
verl Qwen3.5-35B-A3B Megatron GRPO script. https://github.com/verl-project/verl/blob/fa856c3d97fbf93c059322298cc24bec3a944bfe/examples/grpo_trainer/run_qwen3_5_35b_megatron.sh ↩↩
-
Megatron-Core
TransformerConfig, recompute and MoE/GDN-related fields. https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/core/transformer/transformer_config.py ↩ -
Narayanan et al., Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. https://arxiv.org/abs/2104.04473 ↩